Cómo extraer datos de productos de Amazon utilizando Massive proxis

Jason Grad
Administrador de red proxy
February 26, 2025

Amazon proporciona una amplia colección de datos de productos (datos de Amazon) que son un recurso valioso para las empresas, los investigadores y los especialistas en marketing. Amazon requiere una cuidadosa consideración de sus medidas contra el scraping. En esta guía se explica cómo utilizar proxies masivos para realizar solicitudes HTTP eficaces y recopilar datos de las páginas de productos de Amazon, evitando al mismo tiempo los bloqueos de IP.
¡Vamos a sumergirnos!
Cuando se trata del raspado web de Amazon, hay varias aplicaciones valiosas:
Los proxies son cruciales para el raspado web de Amazon porque:
Extraer datos de Amazon no es fácil debido a las diversas medidas de protección vigentes. Estos son algunos de los obstáculos más comunes con los que te puedes encontrar:
Por ejemplo, escribí un script de Python Playwright para extraer datos de varias páginas de productos en Amazon. Sin embargo, mi raspador finalmente se bloqueó, como se muestra en la imagen de abajo.

Ya no podía extraer los datos, lo cual era realmente frustrante y consumía mucho tiempo. Sin embargo, no te preocupes, analizaremos la solución: usar proxies residenciales masivos para eliminar los datos de manera que pasen desapercibidos.
Al seleccionar proxies para eliminar Amazon, es importante determinar qué tipo es el mejor: residencial o de centro de datos.
Los proxies residenciales utilizan las direcciones IP proporcionadas por los proveedores de servicios de Internet (ISP) a los usuarios reales, lo que hace que parezcan conexiones de usuario genuinas y sea menos probable que se detecten.
Por otro lado, los proxies de centros de datos provienen de centros de datos y, por lo general, son más rápidos y económicos, pero también es menos probable que eviten ser detectados.
Proxies residenciales masivos ofrecen un gran conjunto de direcciones IP, lo que garantiza un alto nivel de anonimato y reduce el riesgo de bloqueo.
Los proxies residenciales masivos ofrecen varios beneficios clave:
Para usar los proxies residenciales masivos para el scraping de Amazon, crea una cuenta en Masivo y seleccione un plan que se adapte a sus necesidades de datos y presupuesto. Una vez que tu cuenta esté activa, dirígete a la sección de inicio rápido:

Puedes ver dos opciones de segmentación: Predeterminado y Filtros de destino. El Filtros de destino ofrecen opciones de filtrado más específicas, que analizaremos más adelante. Por ahora, empecemos con Predeterminado segmentación.
Seleccione el HTTPS protocolo y elige Proxies giratorios. Dado que Amazon emplea medidas antiraspado avanzadas, los proxies rotativos te ayudarán a evitar que te detecten. Esto generará un comando cURL que contiene la URL, el nombre de usuario y la contraseña del servidor. Utilizaremos estas credenciales más adelante cuando implementemos el código.
A continuación, echemos un vistazo a la Filtro de destino opciones. Tiene la flexibilidad de elegir entre más de 195 países. Por lo tanto, selecciona el país, estado, ciudad o código postal que desees para realizar un raspado específico.

Por ejemplo, seleccionemos los Estados Unidos y la ciudad de Washington para eliminar los productos de Amazon de esa región específica.
Veamos el proceso de creación de un raspador de Python para extraer todos los datos de Amazon utilizando proxies masivos y Playwright. La biblioteca Playwright es muy útil para automatizar las interacciones del navegador, especialmente para el contenido cargado dinámicamente.
Extraeremos los siguientes datos de cada producto de Amazon: nombre del producto, valoración, número de reseñas, precio, cupón (si está disponible) y enlace al producto.

Para empezar, asegúrese de tener Python instalado en su máquina. A continuación, instala Playwright y los binarios de navegador necesarios:
pip install playwright
playwright installEn tu archivo de Python, importa las bibliotecas necesarias para la programación asincrónica y la automatización del navegador:
import asyncio
from playwright.async_api import async_playwrightDefina una función asincrónica denominada amazon_shopping_search. Esta función utilizará una consulta de búsqueda y un dominio opcional (el predeterminado es «com»):
async def amazon_shopping_search(search_query, domain='com'):
Formatee la consulta de búsqueda sustituyendo los espacios por + para crear una URL válida para la búsqueda:
q = search_query.replace(" ", "+")
base_url = f"<https://www.amazon>.{domain}/s?k={q}"Inicie el navegador con la configuración de proxy y añada las credenciales de su cuenta de Massive.
async with async_playwright() as p:
browser = await p.chromium.launch(
headless=True,
proxy={
"server": "<https://network.joinmassive.com:65535>",
"username": "YOUR_MASSIVE_USERNAME",
"password": "YOUR_MASSIVE_PASSWORD"
}
)Cuando se inicie, todas las solicitudes realizadas por el navegador pasarán por el servidor proxy especificado, lo que ayuda a mantener el anonimato.
Cree una nueva página en el navegador e inicialice una variable para rastrear el número de página actual:
page = await browser.new_page()
page_number = 1
Implemente un bucle que continúe hasta que no haya más páginas que raspar. Para cada iteración, construye la URL de la página actual y navega hasta ella:
Para cada producto de la página, extrae varios detalles como el nombre, el precio, la valoración, las reseñas, el cupón y el enlace mediante selectores de CSS. Si un detalle no está disponible, asigna «N/A».
A continuación te explicamos cómo puedes extraer cada información:
while True:
url = f"{base_url}&page={page_number}"
print(f"Scraping page {page_number}...")
await page.goto(url, wait_until="domcontentloaded")
Fragmento de código:
name = await product.query_selector("[data-cy=title-recipe]")
name = await name.inner_text() if name else "N/A"

Fragmento de código:
current_price = await product.query_selector(".a-price > .a-offscreen")
current_price = await current_price.inner_text() if current_price else "N/A"
Fragmento de código:
rating = await product.query_selector("[data-cy=reviews-ratings-slot]")
rating = await rating.inner_text() if rating else "N/A"
Fragmento de código:
reviews = await product.query_selector(
".rush-component > div > span > a > span, a.a-link-normal > span.a-size-base"
)
reviews = await reviews.inner_text() if reviews else "N/A"

Fragmento de código:
coupon = await product.query_selector(".s-coupon-unclipped")
coupon = await coupon.inner_text() if coupon else "N/A"

Fragmento de código:
link = await product.query_selector("a.a-link-normal")
if link:
full_link = await link.get_attribute("href")
link = (
f'<https://www.amazon>.{domain}{full_link.split("/ref=")[0]}'
if full_link
else "N/A"
)
else:
link = "N/A"
Busca un enlace a la página siguiente. Si no existe, sal del círculo:
next_page = await page.query_selector(".s-pagination-next")
if not next_page:
print("No more pages to scrape.")
breakDespués de raspar todas las páginas, ¡cierra el navegador!
await browser.close()Por último, defina una función asincrónica principal que inicie el proceso de raspado con una consulta de búsqueda específica. Ejecute esta función para iniciar el raspado:
async def main():
await amazon_shopping_search(search_query="office chair", domain="com")
# Run the main function
asyncio.run(main())El siguiente paso es guardar estos datos en un archivo CSV, lo que permite un mayor análisis y procesamiento de datos. Usa el módulo csv integrado de Python para guardar los datos extraídos en un archivo CSV.
import csv
# Open the CSV file once before the loop
with open('product_data.csv', mode='w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
# Write the header
writer.writerow(['Name', 'Current Price', 'Rating',
'Reviews', 'Coupon', 'Link'])
# ... existing code ...
for product in products:
# ... existing code ...
# Write the data if the product is valid and not sponsored
if name != "N/A" and "Sponsored" not in name:
writer.writerow(
[name, current_price, rating, reviews, coupon, link])
# ... existing code ...
Eche un vistazo al código completo para extraer los datos de los productos de Amazon:
import asyncio
from playwright.async_api import async_playwright
import csv
# Function to search for products on Amazon
async def amazon_shopping_search(search_query, domain="com"):
# Replace spaces in the search query with '+'
q = search_query.replace(" ", "+")
# Construct the base URL for the search
base_url = f"<https://www.amazon>.{domain}/s?k={q}"
# Launch a headless browser
async with async_playwright() as p:
browser = await p.chromium.launch(
headless=True,
# Using Massive proxy to avoid IP blocking
proxy={
"server": "<https://network.joinmassive.com:65535>",
"username": "YOUR_MASSIVE_USERNAME",
"password": "YOUR_MASSIVE_PASSWORD",
},
)
# Create a new page in the browser
page = await browser.new_page()
# Initialize the page number
page_number = 1
# Open the CSV file for writing
with open("product_data.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
# Write the header row
writer.writerow(
["Name", "Current Price", "Rating", "Reviews", "Coupon", "Link"]
)
# Start scraping the pages
while True:
# Construct the URL for the current page
url = f"{base_url}&page={page_number}"
print(f"Scraping page {page_number}...")
# Navigate to the current page
await page.goto(url, wait_until="domcontentloaded")
# Take a screenshot of the page
await page.screenshot(path="image.png")
# Wait for the main results container to load
await page.wait_for_selector(".s-main-slot")
# Get all the products on the page
products = await page.query_selector_all(".s-result-item")
# Iterate over each product
for product in products:
# Get the name of the product
name = await product.query_selector("[data-cy=title-recipe]")
name = await name.inner_text() if name else "N/A"
# Get the current price of the product
current_price = await product.query_selector(
".a-price > .a-offscreen"
)
current_price = (
await current_price.inner_text() if current_price else "N/A"
)
# Get the rating of the product
rating = await product.query_selector(
"[data-cy=reviews-ratings-slot]"
)
rating = await rating.inner_text() if rating else "N/A"
# Get the reviews of the product
reviews = await product.query_selector(
".rush-component > div > span > a > span, a.a-link-normal > span.a-size-base"
)
reviews = await reviews.inner_text() if reviews else "N/A"
# Get the coupon of the product
coupon = await product.query_selector(".s-coupon-unclipped")
coupon = await coupon.inner_text() if coupon else "N/A"
# Get the link of the product
link = await product.query_selector("a.a-link-normal")
if link:
full_link = await link.get_attribute("href")
link = full_link.split("/ref=")[0] if full_link else "N/A"
link = f"<https://www.amazon>.{domain}{link}"
else:
link = "N/A"
# Write the product data to the CSV file
if name != "N/A" and "Sponsored" not in name:
writer.writerow(
[name, current_price, rating, reviews, coupon, link]
)
# Check if there is a next page
next_page = await page.query_selector(".s-pagination-next")
if not next_page:
print("No more pages to scrape.")
break
page_number += 1
print("Scraping completed successfully.")
# Close the browser
await browser.close()
# Main function to start the scraping process
async def main():
# Start the Amazon shopping search with the specified query and domain
await amazon_shopping_search(search_query="office chair", domain="com")
# Run the main function
asyncio.run(main())
Función #Main para iniciar el proceso de raspado
definición asíncrona principal ():
página = esperar navegador.nuevo_page () # Inicializa el número de página page_number = 1
# Create a new page in the browser
# Create a new page in the browser
«servidor»:»https://network.joinmassive.com:65535«, «username»: «YOUR_MASSIVE_USERNAME», «password»: «YOUR_MASSIVE_PASSWORD»,
q = search_query.replace(" ", "+")
# Construct the base URL for the search
base_url = f"<https://www.amazon>.{domain}/s?k={q}"
# Launch a headless browser
async with async_playwright() as p:
importar asyncio desde playwright.async_api importar async_playwright importar csv
Una vez que el código se ejecute correctamente, guardará todos los datos del producto extraídos en un archivo CSV:
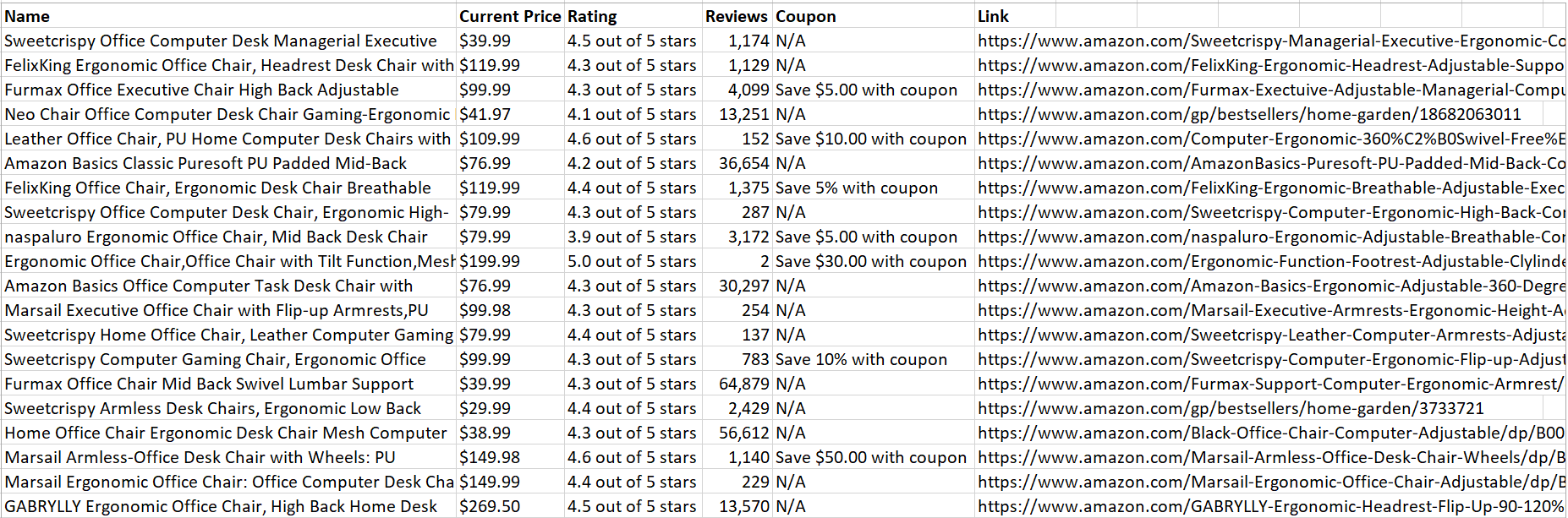
¡Bonito! Los datos son fáciles de analizar y leer.
En este artículo se explica cómo aprovechar los proxies masivos puede ayudarlo a extraer datos valiosos y, al mismo tiempo, minimizar el riesgo de detección y bloqueo. Para obtener una guía detallada sobre el uso de los proxies masivos, asegúrate de visitar nuestra documentación oficial.
No te olvides de explorar Masivo soluciones de representación confiables y éticas. ¡Échales un vistazo y regístrate hoy mismo!

Massive es una marca registrada de Massive Computing, Inc.
.png)

