Como coletar dados de produtos da Amazon usando proxies massivos

Jason Grad
Proxy Network Manager
February 26, 2025

A Amazon fornece uma vasta coleção de dados de produtos (dados da Amazon) que é um recurso valioso para empresas, pesquisadores e profissionais de marketing. Captura de dados na Web A Amazon exige uma análise cuidadosa de suas medidas anti-raspagem. Este guia explicará como usar proxies massivos para solicitações HTTP eficazes e coletar dados das páginas de produtos da Amazon, evitando bloqueios de IP.
Vamos mergulhar!
Quando se trata de web scraping na Amazon, existem vários aplicativos valiosos:
Os proxies são cruciais para a captura na web da Amazon porque eles:
Coletar dados da Amazon não é fácil devido às várias medidas de proteção em vigor. Aqui estão alguns obstáculos comuns que você pode encontrar:
Por exemplo, escrevi um script do Python Playwright para coletar dados de várias páginas de produtos na Amazon. No entanto, meu raspador acabou ficando bloqueado, conforme mostrado na imagem abaixo.

Eu não conseguia mais coletar os dados, o que era muito frustrante e demorado. Mas não se preocupe: analisaremos a solução: usar proxies residenciais massivos para coletar dados sob o radar.
Ao selecionar proxies para capturar a Amazon, é importante determinar qual tipo é melhor: residencial ou datacenter.
Os proxies residenciais usam endereços IP fornecidos pelos provedores de serviços de Internet (ISPs) para usuários reais, fazendo com que apareçam como conexões de usuário genuínas e tenham menos probabilidade de serem detectados.
Por outro lado, os proxies de datacenter são provenientes de data centers e geralmente são mais rápidos e baratos, mas também têm menos probabilidade de evitar a detecção.
Proxies residenciais massivos oferecem um grande conjunto de endereços IP, garantindo alto anonimato e reduzindo o risco de bloqueio.
Proxies residenciais massivos oferecem vários benefícios importantes:
Para usar proxies residenciais massivos para captura de dados na Amazon, crie uma conta no Maciço e selecione um plano que atenda às suas necessidades de dados e orçamento. Depois que sua conta estiver ativa, vá para a seção de início rápido:

Você pode ver duas opções de segmentação: Padrão e Filtros de destino. O Filtros de destino oferecem opções de filtragem mais específicas, que exploraremos mais adiante. Por enquanto, vamos começar com o Padrão segmentação.
Selecione o HTTPS protocolo e escolha Proxies rotativos. Como a Amazon emprega medidas anti-raspagem avançadas, os proxies rotativos ajudarão você a evitar a detecção. Isso gerará um comando cURL contendo a URL, o nome de usuário e a senha do servidor. Usaremos essas credenciais posteriormente ao implementar o código.
A seguir, vamos dar uma olhada no Filtro de destino opções. Você tem a flexibilidade de escolher entre mais de 195 países. Portanto, selecione o país, estado, cidade ou CEP desejado para a coleta direcionada.

Por exemplo, vamos selecionar os Estados Unidos e a cidade de Washington para extrair produtos da Amazon dessa região específica.
Vamos dar uma olhada no processo de criação de um raspador Python para coletar todos os dados da Amazon usando proxies Massive e Playwright. A biblioteca Playwright é muito útil para automatizar as interações do navegador, especialmente para conteúdo carregado dinamicamente.
Coletaremos os seguintes dados de cada produto da Amazon: nome do produto, classificação, número de avaliações, preço, cupom (se disponível) e link do produto.

Para começar, certifique-se de ter o Python instalado em sua máquina. Em seguida, instale o Playwright e os binários necessários do navegador:
pip install playwright
playwright installEm seu arquivo Python, importe as bibliotecas necessárias para programação assíncrona e automação do navegador:
import asyncio
from playwright.async_api import async_playwrightDefina uma função assíncrona chamada amazon_shopping_search. Essa função aceitará uma consulta de pesquisa e um domínio opcional (o padrão é 'com'):
async def amazon_shopping_search(search_query, domain='com'):
Formate a consulta de pesquisa substituindo espaços por + para criar um URL válido para a pesquisa:
q = search_query.replace(" ", "+")
base_url = f"<https://www.amazon>.{domain}/s?k={q}"Inicie o navegador com suas configurações de proxy e adicione suas credenciais de conta Massive.
async with async_playwright() as p:
browser = await p.chromium.launch(
headless=True,
proxy={
"server": "<https://network.joinmassive.com:65535>",
"username": "YOUR_MASSIVE_USERNAME",
"password": "YOUR_MASSIVE_PASSWORD"
}
)Quando iniciadas, todas as solicitações feitas pelo navegador passarão pelo servidor proxy especificado, ajudando a manter o anonimato.
Crie uma nova página no navegador e inicialize uma variável para rastrear o número da página atual:
page = await browser.new_page()
page_number = 1
Implemente um loop que continue até que não haja mais páginas para raspar. Para cada iteração, construa a URL da página atual e navegue até ela:
Para cada produto na página, extraia vários detalhes, como nome, preço, classificação, avaliações, cupom e link usando seletores CSS. Se um detalhe não estiver disponível, atribua “N/A”.
Veja como você pode extrair cada informação:
while True:
url = f"{base_url}&page={page_number}"
print(f"Scraping page {page_number}...")
await page.goto(url, wait_until="domcontentloaded")
Trecho de código:
name = await product.query_selector("[data-cy=title-recipe]")
name = await name.inner_text() if name else "N/A"

Trecho de código:
current_price = await product.query_selector(".a-price > .a-offscreen")
current_price = await current_price.inner_text() if current_price else "N/A"
Trecho de código:
rating = await product.query_selector("[data-cy=reviews-ratings-slot]")
rating = await rating.inner_text() if rating else "N/A"
Trecho de código:
reviews = await product.query_selector(
".rush-component > div > span > a > span, a.a-link-normal > span.a-size-base"
)
reviews = await reviews.inner_text() if reviews else "N/A"

Trecho de código:
coupon = await product.query_selector(".s-coupon-unclipped")
coupon = await coupon.inner_text() if coupon else "N/A"

Trecho de código:
link = await product.query_selector("a.a-link-normal")
if link:
full_link = await link.get_attribute("href")
link = (
f'<https://www.amazon>.{domain}{full_link.split("/ref=")[0]}'
if full_link
else "N/A"
)
else:
link = "N/A"
Verifique se há um link para a próxima página. Se não existir, saia do circuito:
next_page = await page.query_selector(".s-pagination-next")
if not next_page:
print("No more pages to scrape.")
breakDepois de raspar todas as páginas, feche o navegador!
await browser.close()Por fim, defina uma função assíncrona principal que inicie o processo de coleta com uma consulta de pesquisa específica. Execute esta função para iniciar a raspagem:
async def main():
await amazon_shopping_search(search_query="office chair", domain="com")
# Run the main function
asyncio.run(main())A próxima etapa é salvar esses dados em um arquivo CSV, o que permite análises e processamento de dados adicionais. Use o módulo csv integrado do Python para salvar os dados extraídos em um arquivo CSV.
import csv
# Open the CSV file once before the loop
with open('product_data.csv', mode='w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
# Write the header
writer.writerow(['Name', 'Current Price', 'Rating',
'Reviews', 'Coupon', 'Link'])
# ... existing code ...
for product in products:
# ... existing code ...
# Write the data if the product is valid and not sponsored
if name != "N/A" and "Sponsored" not in name:
writer.writerow(
[name, current_price, rating, reviews, coupon, link])
# ... existing code ...
Dê uma olhada no código completo para coletar dados de produtos da Amazon:
import asyncio
from playwright.async_api import async_playwright
import csv
# Function to search for products on Amazon
async def amazon_shopping_search(search_query, domain="com"):
# Replace spaces in the search query with '+'
q = search_query.replace(" ", "+")
# Construct the base URL for the search
base_url = f"<https://www.amazon>.{domain}/s?k={q}"
# Launch a headless browser
async with async_playwright() as p:
browser = await p.chromium.launch(
headless=True,
# Using Massive proxy to avoid IP blocking
proxy={
"server": "<https://network.joinmassive.com:65535>",
"username": "YOUR_MASSIVE_USERNAME",
"password": "YOUR_MASSIVE_PASSWORD",
},
)
# Create a new page in the browser
page = await browser.new_page()
# Initialize the page number
page_number = 1
# Open the CSV file for writing
with open("product_data.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
# Write the header row
writer.writerow(
["Name", "Current Price", "Rating", "Reviews", "Coupon", "Link"]
)
# Start scraping the pages
while True:
# Construct the URL for the current page
url = f"{base_url}&page={page_number}"
print(f"Scraping page {page_number}...")
# Navigate to the current page
await page.goto(url, wait_until="domcontentloaded")
# Take a screenshot of the page
await page.screenshot(path="image.png")
# Wait for the main results container to load
await page.wait_for_selector(".s-main-slot")
# Get all the products on the page
products = await page.query_selector_all(".s-result-item")
# Iterate over each product
for product in products:
# Get the name of the product
name = await product.query_selector("[data-cy=title-recipe]")
name = await name.inner_text() if name else "N/A"
# Get the current price of the product
current_price = await product.query_selector(
".a-price > .a-offscreen"
)
current_price = (
await current_price.inner_text() if current_price else "N/A"
)
# Get the rating of the product
rating = await product.query_selector(
"[data-cy=reviews-ratings-slot]"
)
rating = await rating.inner_text() if rating else "N/A"
# Get the reviews of the product
reviews = await product.query_selector(
".rush-component > div > span > a > span, a.a-link-normal > span.a-size-base"
)
reviews = await reviews.inner_text() if reviews else "N/A"
# Get the coupon of the product
coupon = await product.query_selector(".s-coupon-unclipped")
coupon = await coupon.inner_text() if coupon else "N/A"
# Get the link of the product
link = await product.query_selector("a.a-link-normal")
if link:
full_link = await link.get_attribute("href")
link = full_link.split("/ref=")[0] if full_link else "N/A"
link = f"<https://www.amazon>.{domain}{link}"
else:
link = "N/A"
# Write the product data to the CSV file
if name != "N/A" and "Sponsored" not in name:
writer.writerow(
[name, current_price, rating, reviews, coupon, link]
)
# Check if there is a next page
next_page = await page.query_selector(".s-pagination-next")
if not next_page:
print("No more pages to scrape.")
break
page_number += 1
print("Scraping completed successfully.")
# Close the browser
await browser.close()
# Main function to start the scraping process
async def main():
# Start the Amazon shopping search with the specified query and domain
await amazon_shopping_search(search_query="office chair", domain="com")
# Run the main function
asyncio.run(main())
Função #Main para iniciar o processo de raspagem
async def main ():
página = aguardar navegador.novo_page () # Inicialize o número da página page_number = 1
# Create a new page in the browser
# Create a new page in the browser
“servidor”:”https://network.joinmassive.com:65535“, “nome de usuário”: “YOUR_MASSIVE_USERNAME”, “senha”: “YOUR_MASSIVE_PASSWORD”,
q = search_query.replace(" ", "+")
# Construct the base URL for the search
base_url = f"<https://www.amazon>.{domain}/s?k={q}"
# Launch a headless browser
async with async_playwright() as p:
importar asyncio de playwright.async_api importar async_playwright importar csv
Quando o código for executado com sucesso, ele salvará todos os dados do produto copiados em um arquivo CSV:
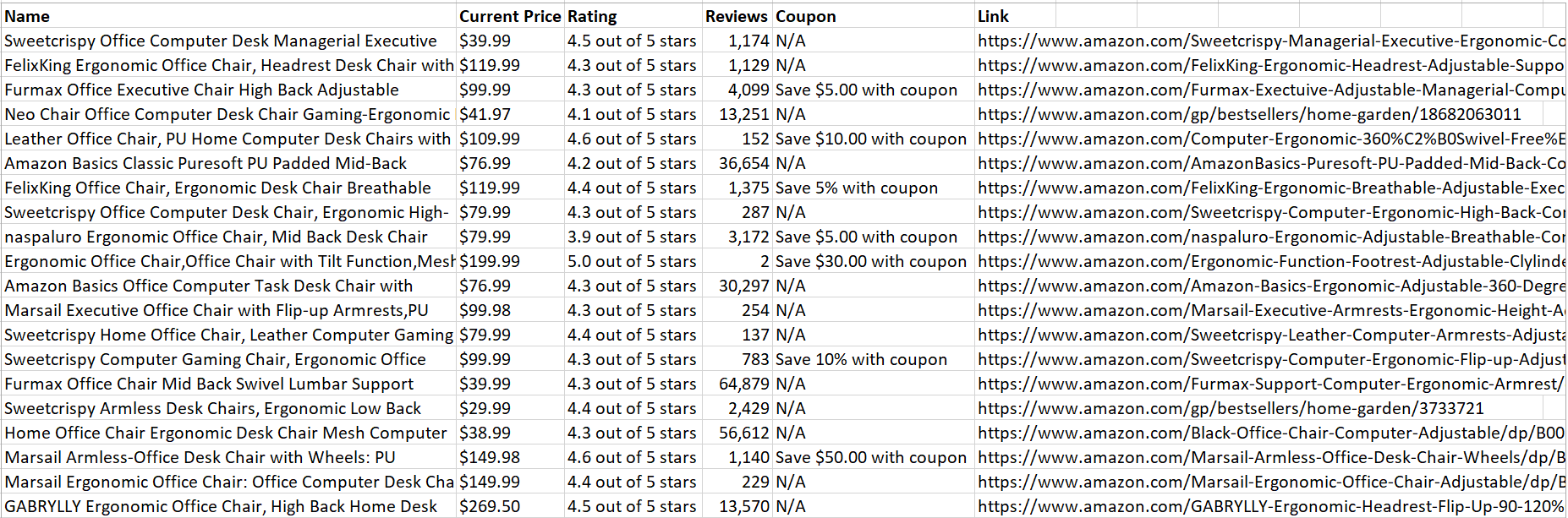
Agradável! Os dados são fáceis de analisar e ler.
Este artigo discutiu como o uso de proxies massivos pode ajudar a extrair dados valiosos e, ao mesmo tempo, minimizar o risco de detecção e bloqueio. Para obter orientação detalhada sobre o uso de proxies massivos, não deixe de visitar nosso documentação oficial.
Não se esqueça de explorar Maciço soluções de proxy confiáveis e éticas. Confira e inscreva-se hoje mesmo!

Copyright Massive; Massive is a registered trademark of Massive Computing, Inc.
.png)

