

How to Scrape Amazon Product Data Using Massive Proxies

Jason Grad
Co-founder
February 26, 2025
Amazon provides a vast collection of product data (Amazon data) that is a valuable resource for businesses, researchers, and marketers. Web scraping Amazon requires careful consideration of its anti-scraping measures. This guide will explain how to use Massive proxies for effective HTTP requests and gather data from Amazon product pages while avoiding IP blocks.
Let’s dive in!
When it comes to web scraping Amazon, there are various valuable applications:
Proxies are crucial for web scraping Amazon because they:
Scraping data from Amazon is not easy due to various protective measures in place. Here are some common hurdles you might encounter:
For instance, I wrote a Python Playwright script to scrape data from multiple product pages on Amazon. However, my scraper eventually got blocked, as shown in the image below.
I was no longer able to scrape the data, which was really frustrating and time-consuming. Don't worry, though—we'll look at the solution: using Massive Residential Proxies to scrape data under the radar.
When selecting proxies to scrape Amazon, it's important to determine which type is best: residential or datacenter.
Residential proxies use IP addresses provided by Internet Service Providers (ISPs) to real users, making them appear as genuine user connections and less likely to be detected.
On the other hand, datacenter proxies are sourced from data centers and are generally faster and cheaper, but they are also less likely to avoid detection.
Massive residential proxies offer a large pool of IP addresses, ensuring high anonymity and reducing the risk of being blocked.
Massive residential proxies offer several key benefits:
If you’re new to Massive, sign up for an account. Choose a plan for your needs.
Note: We offer a 2 GB free trial for companies. To get started, fill out this form. If you need more bandwidth, contact our sales team, and we’ll assist you.
After signing up, go to the Massive Dashboard to retrieve your proxy credentials (username and password).
Configuration Steps:
Visit the Quickstart section to customize your proxy settings:
Once configured, you'll get a ready-to-use cURL command for your specific use case.
For advanced features like location-based targeting and sticky sessions, refer to the Massive Documentation. The docs provide step-by-step instructions for getting the most out of Massive Residential Proxies.
With this setup, you can use Massive Proxies to scrape Amazon products data from the specific region.
Let’s look at the process of building a Python scraper for scraping all the data from Amazon using Massive proxies and Playwright. The Playwright library is very useful for automating browser interactions, especially for dynamically loaded content.
We'll scrape the following data from each Amazon product: Product Name, Rating, Number of Reviews, Price, Coupon (if available), and Product Link.
To begin, make sure you have Python installed on your machine. Next, install Playwright and its necessary browser binaries:
pip install playwright
playwright installIn your Python file, import the necessary libraries for asynchronous programming and browser automation:
import asyncio
from playwright.async_api import async_playwrightDefine an asynchronous function named amazon_shopping_search. This function will take a search query and an optional domain (defaulting to 'com'):
async def amazon_shopping_search(search_query, domain='com'):
Format the search query by replacing spaces with + to create a valid URL for the search:
q = search_query.replace(" ", "+")
base_url = f"<https://www.amazon>.{domain}/s?k={q}"Launch the browser with your proxy settings and add your Massive account credentials.
async with async_playwright() as p:
browser = await p.chromium.launch(
headless=True,
proxy={
"server": "https://network.joinmassive.com:65535",
"username": "MASSIVE_USERNAME",
"password": "MASSIVE_PASSWORD",
},
)When launched, all requests made by the browser will go through the specified proxy server, helping maintain anonymity.
Create a new page in the browser and initialize a variable to track the current page number:
page = await browser.new_page()
page_number = 1
Implement a loop that continues until there are no more pages to scrape. For each iteration, construct the URL for the current page and navigate to it:
while True:
url = f"{base_url}&page={page_number}"
print(f"Scraping page {page_number}...")
await page.goto(url, wait_until="domcontentloaded")
For each product on the page, extract various details such as name, price, rating, reviews, coupon, and link using CSS selectors. If a detail is not available, assign "N/A".
Here’s how you can extract each piece of information:
Code snippet:
name = await product.query_selector("[data-cy=title-recipe]")
name = await name.inner_text() if name else "N/A"
Code snippet:
current_price = await product.query_selector(".a-price > .a-offscreen")
current_price = await current_price.inner_text() if current_price else "N/A"
Code snippet:
rating = await product.query_selector("[data-cy=reviews-ratings-slot]")
rating = await rating.inner_text() if rating else "N/A"
Code snippet:
reviews = await product.query_selector(
".rush-component > div > span > a > span, a.a-link-normal > span.a-size-base"
)
reviews = await reviews.inner_text() if reviews else "N/A"
Code snippet:
coupon = await product.query_selector(".s-coupon-unclipped")
coupon = await coupon.inner_text() if coupon else "N/A"
Code snippet:
link = await product.query_selector("a.a-link-normal")
if link:
full_link = await link.get_attribute("href")
link = (
f'<https://www.amazon>.{domain}{full_link.split("/ref=")[0]}'
if full_link
else "N/A"
)
else:
link = "N/A"
Check for a link to the next page. If it doesn’t exist, break out of the loop:
next_page = await page.query_selector(".s-pagination-next")
if not next_page:
print("No more pages to scrape.")
breakAfter scraping all the pages, close the browser!
await browser.close()Finally, define a main asynchronous function that starts the scraping process with a specific search query. Execute this function to initiate scraping:
async def main():
await amazon_shopping_search(search_query="office chair", domain="com")
# Run the main function
asyncio.run(main())The next step is to save this data into a CSV file, which allows for further analysis and data processing. Use Python's built-in csv module to save the extracted data into a CSV file.
import csv
# Open the CSV file once before the loop
with open("product_data.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
# Write the header
writer.writerow(["Name", "Current Price", "Rating", "Reviews", "Coupon", "Link"])
# existing code...
for product in products:
# existing code...
# Write the data if the product is valid and not sponsored
if name != "N/A" and "Sponsored" not in name:
writer.writerow([name, current_price, rating, reviews, coupon, link])
# existing code...Take a look at the complete code for scraping Amazon product data:
import asyncio
from playwright.async_api import async_playwright
import csv
async def amazon_shopping_search(search_query, domain="com"):
q = search_query.replace(" ", "+")
base_url = f"https://www.amazon.{domain}/s?k={q}"
async with async_playwright() as p:
# Launch browser with massive proxy to avoid IP blocking
browser = await p.chromium.launch(
headless=True,
proxy={
"server": "https://network.joinmassive.com:65535",
"username": "PROXY_USERNAME",
"password": "PROXY_PASSWORD",
},
)
page = await browser.new_page()
page_number = 1
with open("product_data.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow(["Name", "Price", "Rating", "Reviews", "Coupon", "Link"])
while True:
url = f"{base_url}&page={page_number}"
print(f"Scraping page {page_number}...")
try:
await page.goto(url, wait_until="networkidle", timeout=60000)
await page.wait_for_selector(".s-result-item")
except Exception as e:
print(f"Navigation failed: {str(e)}")
break
# Get all product elements
products = await page.query_selector_all(".s-result-item")
for product in products:
# Skip sponsored items
is_sponsored = await product.query_selector(
".s-sponsored-label-text"
)
if is_sponsored:
continue
# Extract data with error handling
try:
name_elem = await product.query_selector("h2 a")
name = await name_elem.inner_text() if name_elem else "N/A"
price_elem = await product.query_selector(
".a-price .a-offscreen"
)
price = await price_elem.inner_text() if price_elem else "N/A"
rating_elem = await product.query_selector(
".a-icon-star-small .a-icon-alt"
)
rating = (
await rating_elem.inner_text() if rating_elem else "N/A"
)
reviews_elem = await product.query_selector(
".a-size-small .a-size-base"
)
reviews = (
await reviews_elem.inner_text() if reviews_elem else "N/A"
)
coupon_elem = await product.query_selector(
".s-coupon-unclipped"
)
coupon = (
await coupon_elem.inner_text() if coupon_elem else "N/A"
)
link = await name_elem.get_attribute("href")
link = (
f"https://www.amazon.{domain}{link.split('?')[0]}"
if link
else "N/A"
)
writer.writerow([name, price, rating, reviews, coupon, link])
except Exception as e:
print(f"Error processing product: {str(e)}")
continue
# Pagination handling
next_disabled = await page.query_selector(
".s-pagination-next.s-pagination-disabled"
)
if next_disabled:
print("Reached last page")
break
page_number += 1
if page_number > 5: # Safety limit
print("Reached page limit")
break
await browser.close()
async def main():
await amazon_shopping_search(search_query="office chair", domain="com")
if __name__ == "__main__":
asyncio.run(main())Once the code runs successfully, it will save all the scraped product data into a CSV file:
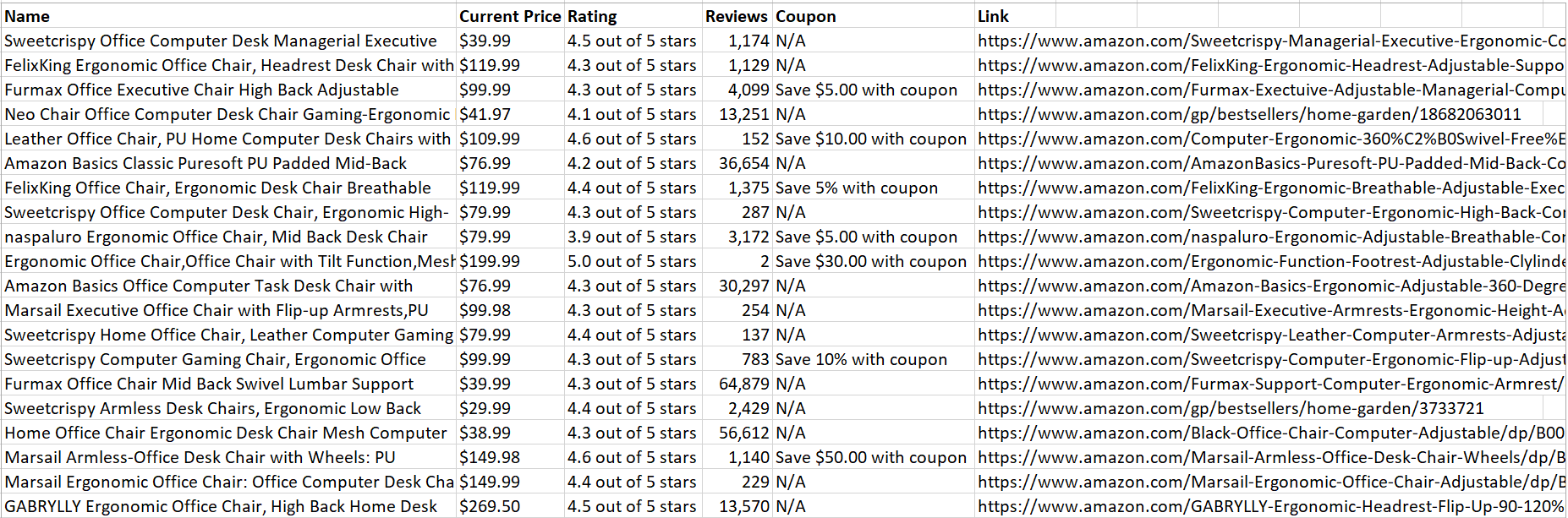
Nice! The data is easy to analyze and read.
This article discussed how leveraging Massive proxies can help you extract valuable data while minimizing the risk of detection and blocking. For more details on proxy configuration or best practices, be sure to visit our official documentation.
Ready to get started? Sign up for Massive Proxies today 🚀
I am the co-founder & CEO of Massive. In addition to working on startups, I am a musician, athlete, mentor, event host, and volunteer.
Copyright Massive; Massive is a registered trademark of Massive Computing, Inc.







