Cómo extraer datos de Zillow con Massive: una guía para principiantes

Jason Grad
Cofundador
March 28, 2025
.png)
Zillow es uno de los sitios web inmobiliarios más grandes de EE. UU., que ofrece un tesoro de listados inmobiliarios, precios de propiedades y análisis de mercado. Sin embargo, eliminar Zillow no es fácil: sus defensas antibots pueden detener rápidamente tus esfuerzos de extracción de datos.
Esta guía le explica cómo extraer los datos de las propiedades de Zillow de manera efectiva utilizando los proxies residenciales de Massive y Python con Playwright. Aprenderás cómo evitar la detección, extraer datos inmobiliarios de forma fiable y escalar tu flujo de trabajo de scraping como un profesional.
Los datos inmobiliarios de Zillow son una mina de oro para:
Ya sea que sea un analista de datos, un inversor inmobiliario o un desarrollador de herramientas de automatización de edificios, extraer datos de Zillow puede proporcionar información valiosa sobre el mercado inmobiliario.
La extracción de datos de Zillow presenta importantes desafíos debido a sus sólidos sistemas antibots:
Este es un ejemplo de lo que ocurre cuando un raspador se bloquea mediante una verificación humana:

Ahí es donde entran en juego los proxies, específicamente los proxies residenciales.
Los proxies actúan como intermediarios entre tu scraper y la web. Son esenciales para el raspado web de Zillow porque ayudan a:
Sin embargo, no todos los proxies se crean de la misma manera.
Por experiencia, los proxies residenciales superan a los de los centros de datos a la hora de eliminar Zillow. He aquí por qué:
Si su objetivo es un raspado consistente y escalable sin bloques, residencial es el camino a seguir.
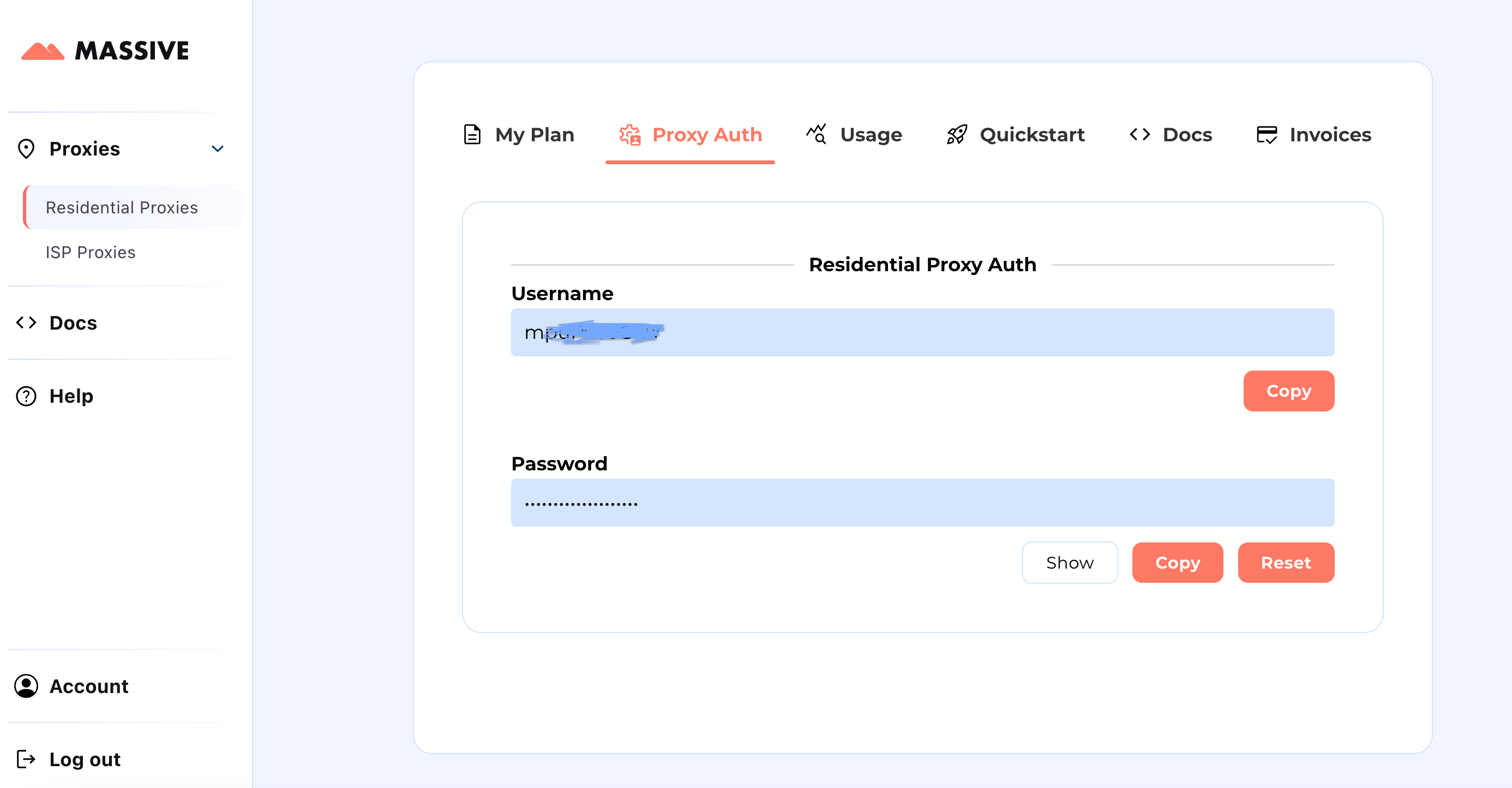
Crea tu cuenta en partners.joinmassive.com y elige un plan que se adapte a tus necesidades. Después de eso, vaya al Panel de control Massive para recuperar sus credenciales de proxy (nombre de usuario y contraseña).
Pasos de configuración:
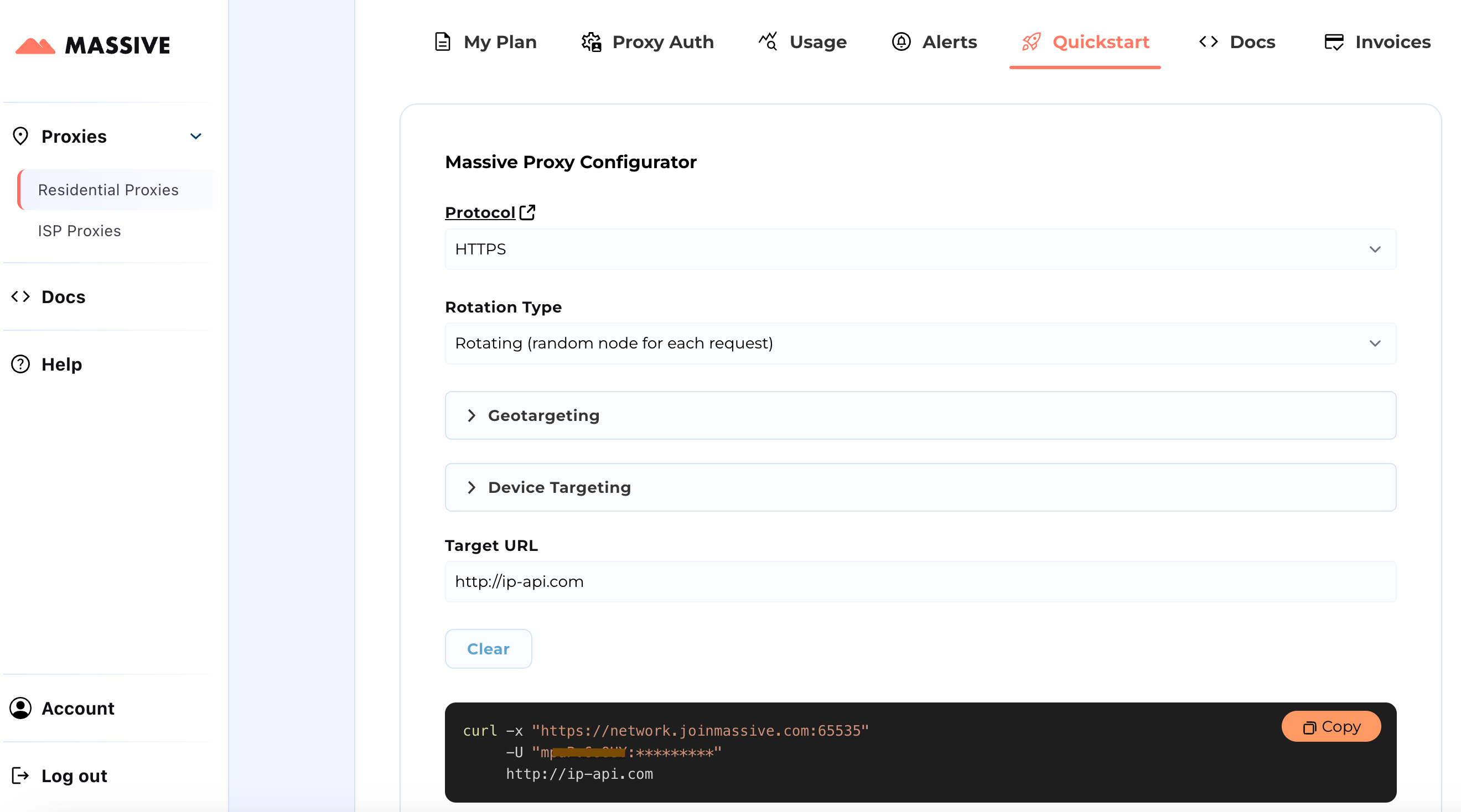
Visite el Inicio rápido sección para personalizar la configuración de su proxy:
Una vez configurado, obtendrá un comando cURL listo para usar para su caso de uso específico.
Para ver funciones avanzadas, como la segmentación basada en la ubicación y las sesiones fijas, consulta la Documentación Massive. Los documentos proporcionan instrucciones paso a paso para aprovechar al máximo los proxies residenciales Massive.
Con esta configuración, puede usar Massive Proxies para extraer los datos de los productos de Zillow de una región específica.
Construyamos un raspador Zillow usando Playwright y proxies Massive. Playwright automatiza las interacciones con los navegadores y gestiona eficazmente el contenido dinámico, mientras que los proxies ayudan a evitar la detección y a eludir las restricciones.
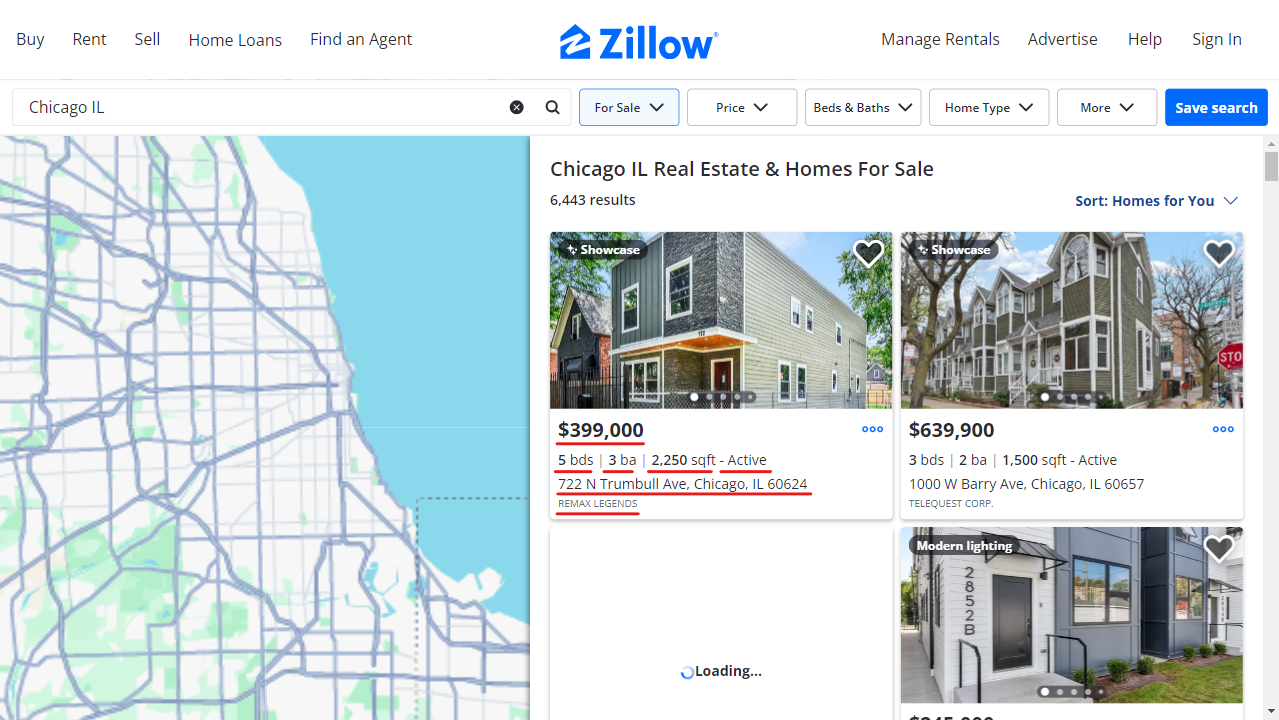
Revisaremos los anuncios de bienes raíces para Chicago Illinois, extrayendo la siguiente información para cada propiedad:
Comience por crear un entorno virtual e instalar los paquetes necesarios. También puede usar Conda o Poetry si lo prefiere.
python -m venv zillow_envsource
zillow_env/bin/activate # Windows: zillow_env\\Scripts\\activate
pip install playwright python-dotenv
playwright install
Crea un .env archivo para almacenar sus credenciales de proxy Massive de forma segura.
PROXY_SERVER="your_proxy_server"
PROXY_USERNAME="your_username"
PROXY_PASSWORD="your_password"
Configure las credenciales de proxy y bloquee los activos innecesarios para optimizar el rendimiento y evitar la detección.
class Config:
PROXY_SERVER = os.getenv("PROXY_SERVER")
PROXY_USERNAME = os.getenv("PROXY_USERNAME")
PROXY_PASSWORD = os.getenv("PROXY_PASSWORD")
BLOCKED_RESOURCES = ["stylesheet", "image", "media", "font", "imageset"]
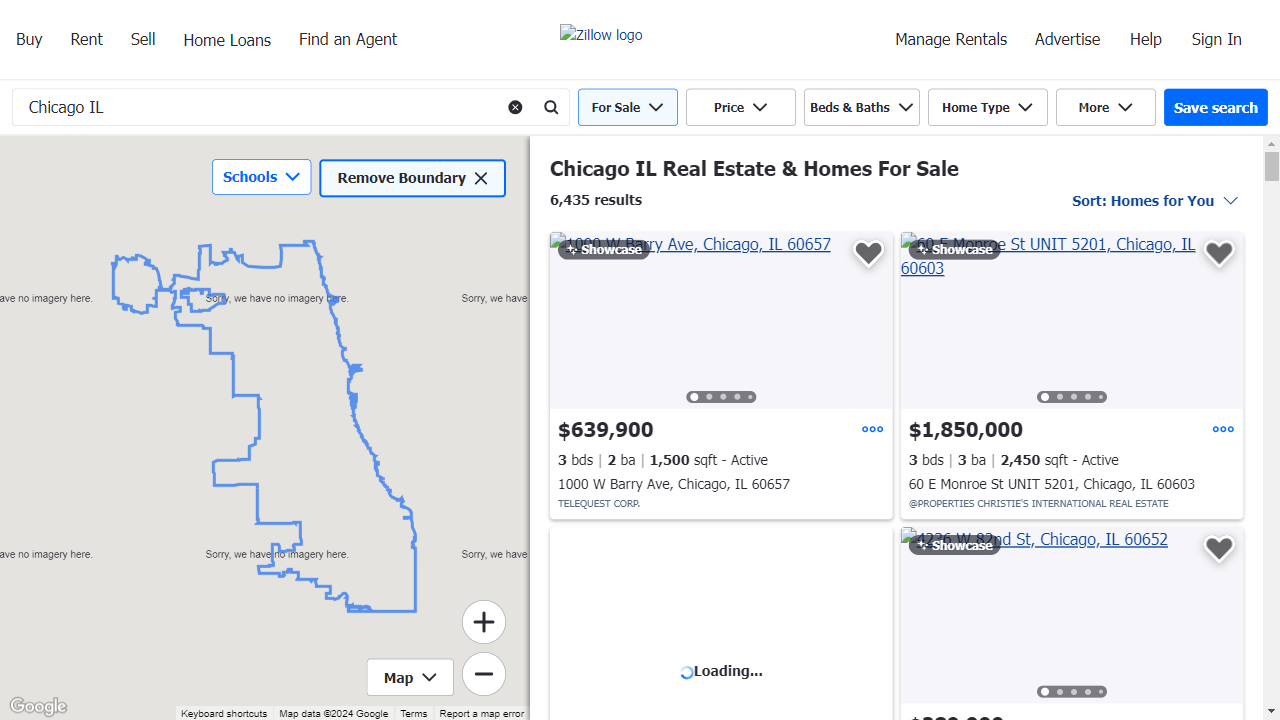
El bloqueo de recursos innecesarios, como fuentes e imágenes, acelera el proceso de raspado.
Este es un ejemplo del aspecto de la página cuando los recursos están bloqueados:
Aquí, definimos un contexto de navegador que dirige las solicitudes a través de Massive y filtra el contenido no deseado.
class AsyncZillowSearchScraper:
def __init__(self, headless: bool = True):
self.headless = headless
self.playwright = None
self.browser = None
self.context = None
async def __aenter__(self):
self.playwright = await async_playwright().start()
browser_config = {"headless": self.headless}
if Config.PROXY_SERVER:
browser_config["proxy"] = {
"server": Config.PROXY_SERVER,
"username": Config.PROXY_USERNAME,
"password": Config.PROXY_PASSWORD,
}
self.browser = await self.playwright.chromium.launch(**browser_config)
self.context = await self.browser.new_context()
await self.context.route("**/*", self._route_handler)
return self
async def _route_handler(self, route):
if route.request.resource_type in Config.BLOCKED_RESOURCES:
await route.abort()
else:
await route.continue_()
Cada propiedad de Zillow se encuentra dentro de un <li> etiqueta. Estos <li> las etiquetas tienen una clase que comienza con ListItem y cada etiqueta representa un único listado de propiedades. Dentro de estos <li> etiquetas, encontrará todos los detalles clave sobre la propiedad, como la dirección, el precio y las características de la propiedad
.
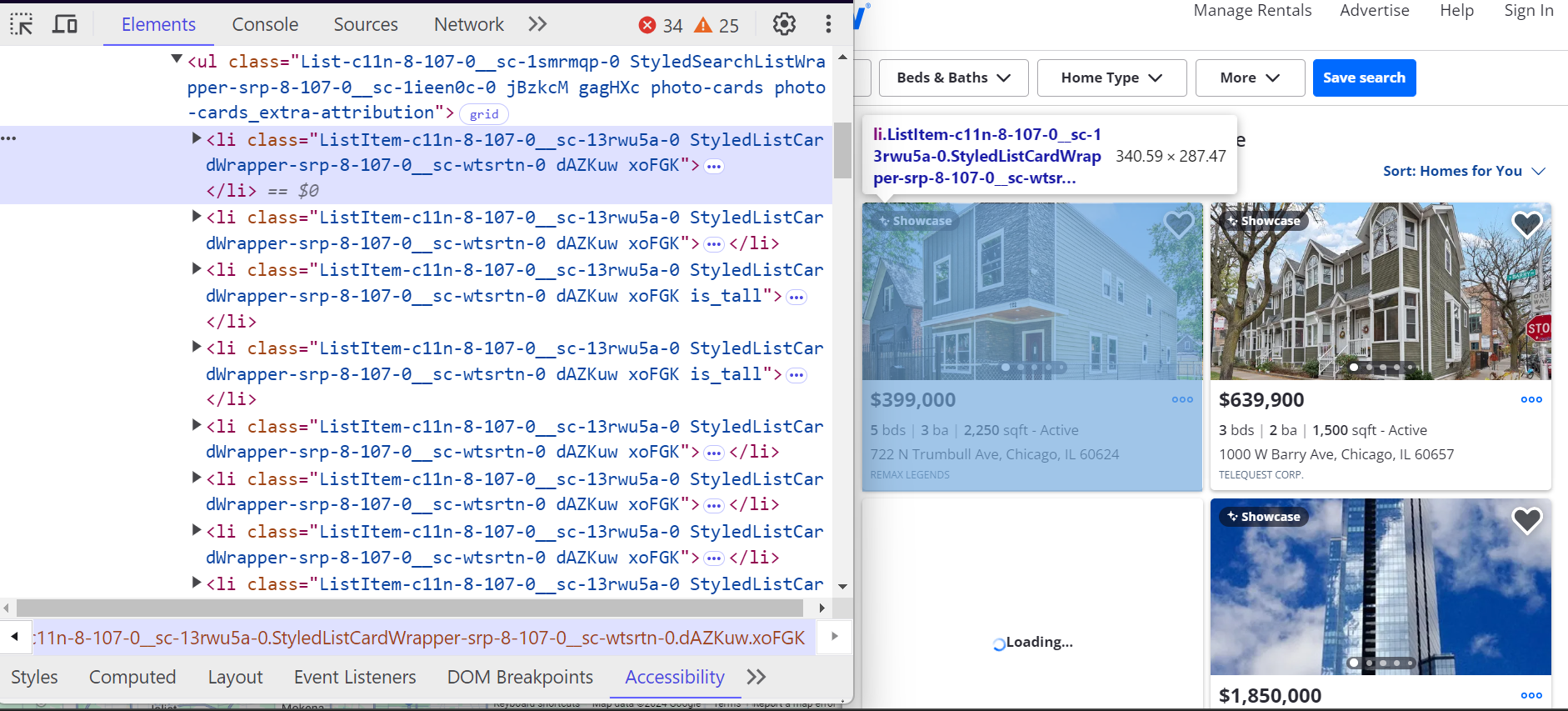
Así es como estos <li> las etiquetas están estructuradas:
Detalles adicionales, como la cantidad de dormitorios, baños y pies cuadrados, se encuentran dentro <ul> listas.
Así es como analizamos los listados de propiedades individuales:
class ListingParser:
@staticmethod
async def extract_listing_details(listing) -> Optional[Dict]:
try:
data_container = await listing.query_selector(
'div[class*="property-card-data"]'
)
if not data_container:
return None
# Extract basic details
details = {
"address": None,
"status": None,
"price": None,
"bedrooms": None,
"bathrooms": None,
"square_feet": None,
"listing_company": None,
"url": None,
}
# Get address
if address_elem := await data_container.query_selector(
'address[data-test="property-card-addr"]'
):
details["address"] = ListingParser.clean_text(
await address_elem.text_content()
)
# Get price
if price_elem := await data_container.query_selector(
'span[data-test="property-card-price"]'
):
details["price"] = ListingParser.clean_text(
await price_elem.text_content()
)
# Get property URL
if url_elem := await data_container.query_selector(
'a[data-test="property-card-link"]'
):
if url := await url_elem.get_attribute("href"):
details["url"] = (
f"<https://www.zillow.com>{url}"
if not url.startswith("http")
else url
)
# ...
return details
except Exception as e:
logger.error(f"Error extracting listing details: {e}")
return None
Simula el desplazamiento para cargar más anuncios de forma dinámica:
async def _scroll_and_get_listings(self, page):
last_count = 0
attempts = 0
MAX_ATTEMPTS = 20
while attempts < MAX_ATTEMPTS:
listings = await page.query_selector_all('article[data-test="property-card"]')
current_count = len(listings)
if current_count == last_count:
break
last_count = current_count
await page.evaluate("window.scrollBy(0, 500)")
await asyncio.sleep(1)
attempts += 1
return listings
Haga clic en la página siguiente (>) botón para navegar por otras páginas.
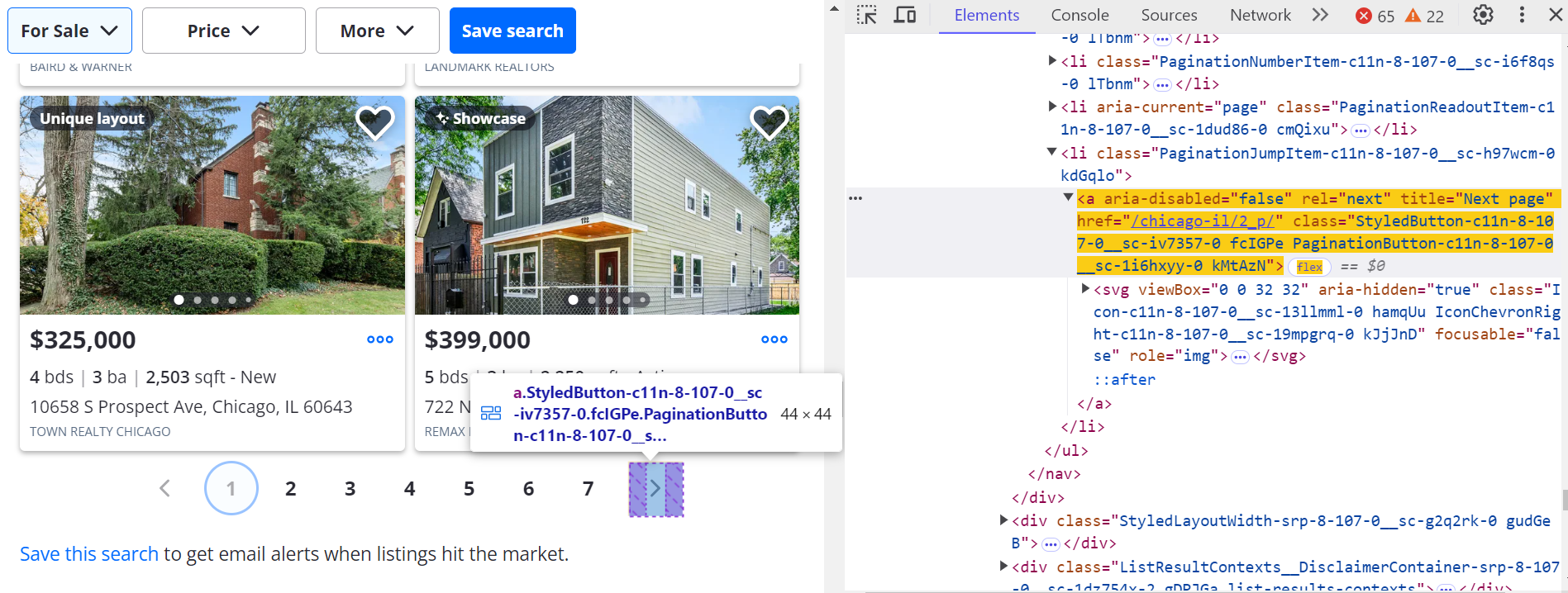
Para ir a la página siguiente:
next_button = await page.query_selector('a[title="Next page"]:not([disabled])')
if next_button:
await next_button.click()
await asyncio.sleep(3)
Guarda los datos extraídos de Zillow en un archivo JSON. También puedes convertirlos a CSV más adelante.
class ResultsSaver:
@staticmethod
def save_results(data, filename="zillow_listings.json"):
with open(filename, "w", encoding="utf-8") as file:
json.dump(data, file, indent=4, ensure_ascii=False)
logger.info(f"Saved {len(data)} listings")
@staticmethod
def load_existing_results(filename="zillow_listings.json"):
try:
if os.path.exists(filename):
with open(filename, "r", encoding="utf-8") as file:
return json.load(file)
except Exception as e:
logger.error(f"Error loading data: {e}")
return []
Une todo en una función principal para lanzar el raspador, extraer datos y guardar los resultados.
async def main():
search_url = "https://www.zillow.com/chicago-il/"
max_pages = None # Set to a number to limit pages
async with AsyncZillowSearchScraper(headless=False) as scraper:
results = await scraper.scrape_search_results(search_url, max_pages=max_pages)
print(f"\\nTotal listings scraped: {len(results)}")
if results:
print("\\nSample listing:")
print(json.dumps(results[0], indent=2, ensure_ascii=False))
if __name__ == "__main__":
asyncio.run(main())
Una vez que hayas configurado y ejecutado correctamente tu raspador Zillow usando proxies Massive, tu resultado tendrá un aspecto similar al siguiente:
[
{
"address": "722 N Trumbull Ave, Chicago, IL 60624",
"status": "Active",
"price": "$399,000",
"bedrooms": "5",
"bathrooms": "3",
"square_feet": "2250",
"listing_company": "REMAX LEGENDS",
"url": "https://www.zillow.com/homedetails/722-N-Trumbull-Ave-Chicago-IL-60624/3810331_zpid/",
}
]Los datos ahora están estructurados y son utilizables, perfectos para análisis inmobiliarios, paneles o herramientas de inversión.
Puede acceder al código completo para extraer datos de Zillow utilizando proxies Massive en La esencia de GitHub.
La recopilación de datos inmobiliarios de Zillow le brinda una ventaja para comprender el mercado, rastrear propiedades y herramientas de automatización de edificios. Con los proxies residenciales de Massive, puedes:
¿Estás listo para construir tu propio raspador de datos de Zillow? Regístrate en Massive Proxies hoy.

Massive es una marca registrada de Massive Computing, Inc.




