Como coletar dados do Zillow com o Massive - um guia para iniciantes

Jason Grad
Co-founder
March 28, 2025
.png)
O Zillow é um dos maiores sites imobiliários dos EUA, oferecendo um tesouro de listagens de imóveis, preços de propriedades e análises de mercado. Mas eliminar o Zillow não é fácil: suas defesas anti-bots podem rapidamente interromper seus esforços de extração de dados.
Este guia explica como coletar dados de propriedades do Zillow de forma eficaz usando Proxies residenciais da Massive e Python com Playwright. Você aprenderá a contornar a detecção, extrair dados imobiliários de forma confiável e escalar seu fluxo de trabalho de coleta como um profissional.
Os dados imobiliários da Zillow são uma mina de ouro para:
Seja você analista de dados, investidor imobiliário ou desenvolvedor de ferramentas de automação de edifícios, coletar dados da Zillow pode fornecer informações valiosas sobre o mercado imobiliário.
A coleta de dados do Zillow apresenta desafios significativos devido aos seus robustos sistemas anti-bot:
Aqui está um exemplo do que acontece quando um raspador é bloqueado pela verificação humana:

É aí que entram os procuradores, especificamente os residenciais.
Os proxies atuam como intermediários entre seu raspador e a web. Eles são essenciais para o web scraping Zillow porque ajudam a:
No entanto, nem todos os proxies são criados da mesma forma.
Por experiência própria, os proxies residenciais superam os de datacenter na eliminação do Zillow. Veja o porquê:
Se sua meta for uma raspagem consistente e escalável sem bloqueios, residencial é o caminho a percorrer.
Crie sua conta em partners.joinmassive.com e escolha um plano para suas necessidades. Depois disso, vá para o Painel enorme para recuperar suas credenciais de proxy (nome de usuário e senha).
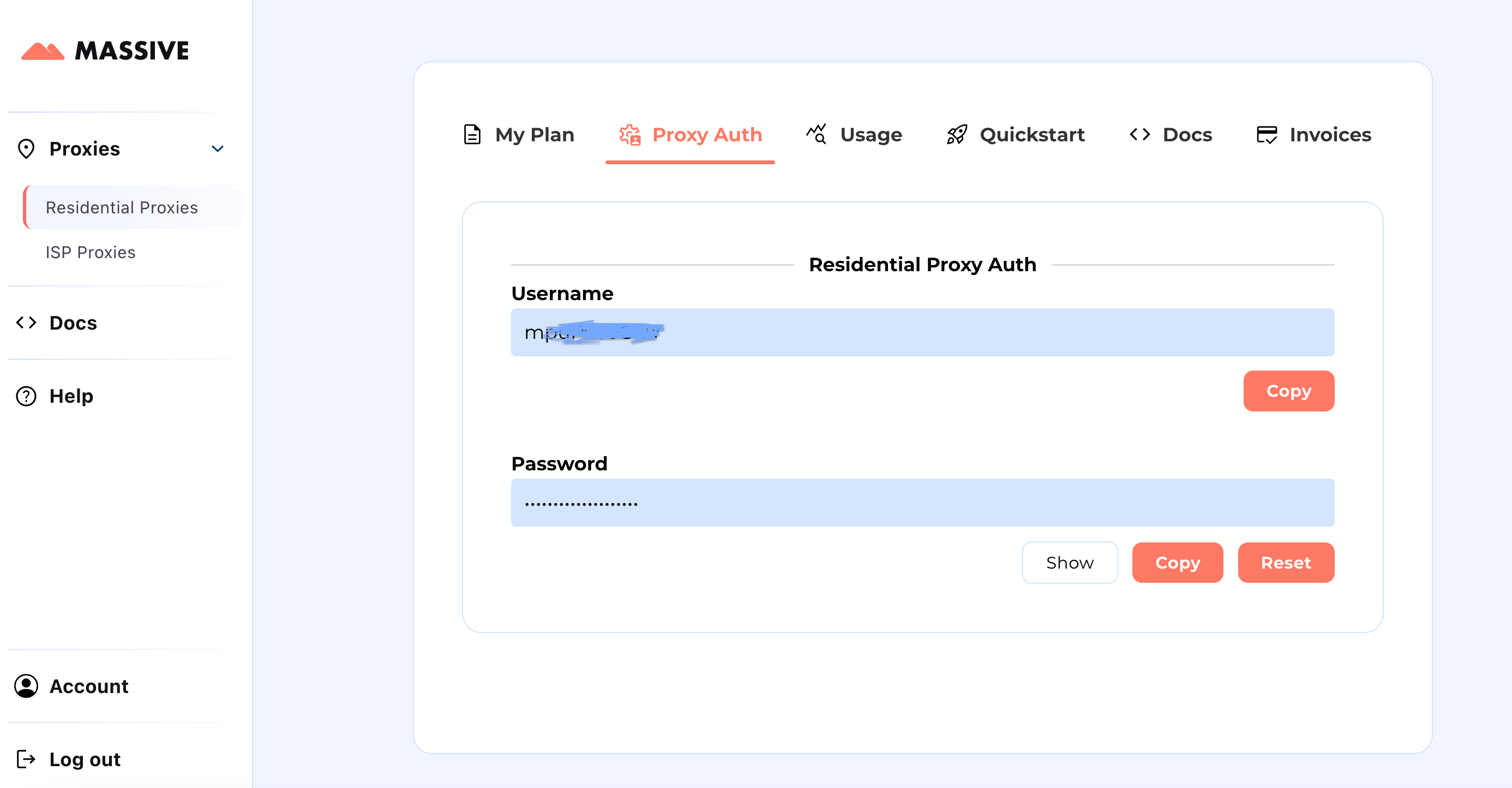
Etapas de configuração:
Visite o Início rápido seção para personalizar suas configurações de proxy:
Depois de configurado, você receberá um comando cURL pronto para uso para seu caso de uso específico.
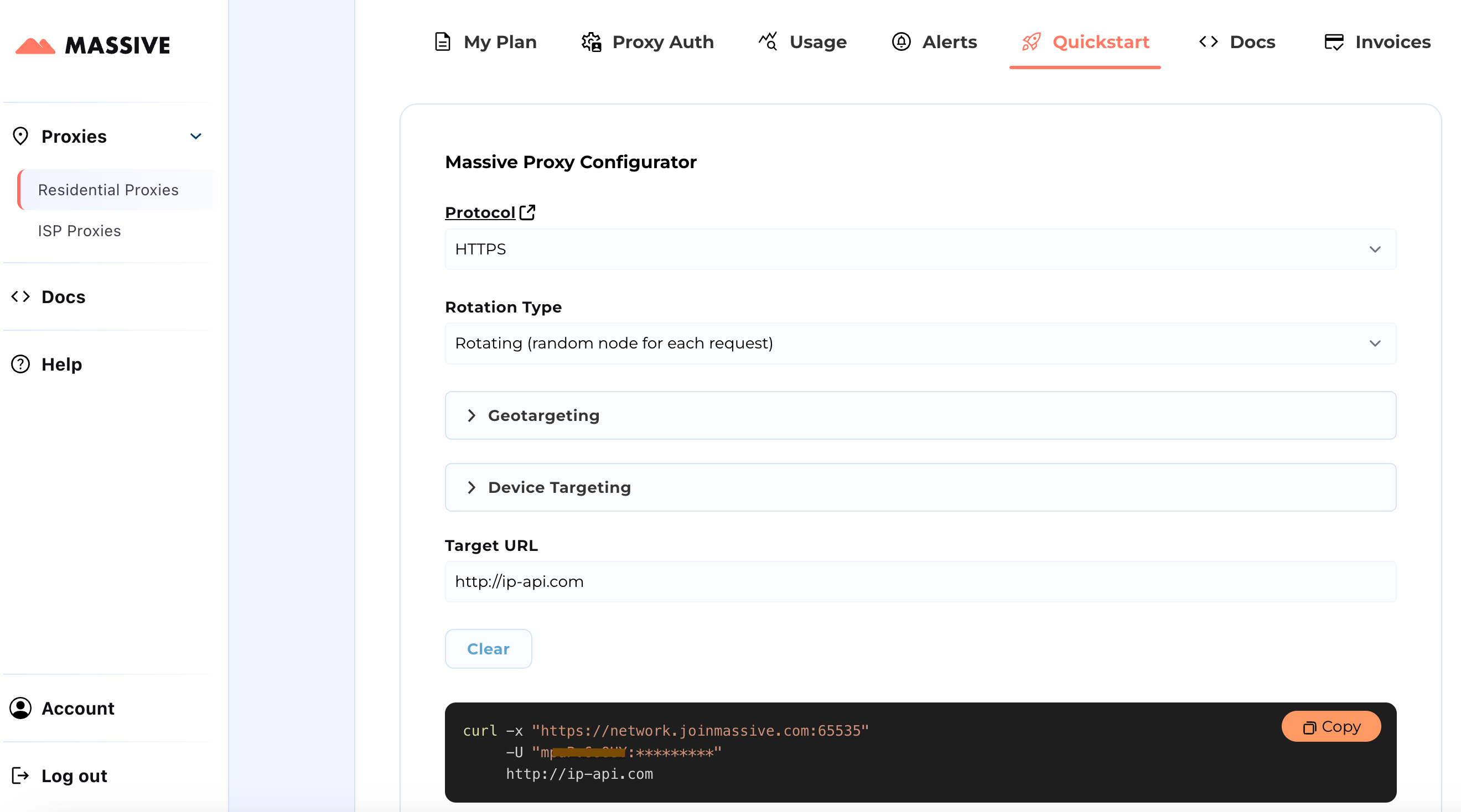
Para recursos avançados, como segmentação com base em localização e sessões fixas, consulte o Documentação Massive. Os documentos fornecem instruções passo a passo para tirar o máximo proveito dos Massive Residential Proxies.
Com essa configuração, você pode usar Massive Proxies para coletar dados de produtos Zillow de uma região específica.
Vamos construir um raspador Zillow usando Dramaturgo e Massive Proxies. O Playwright automatiza as interações do navegador e lida com conteúdo dinâmico de forma eficaz, enquanto os proxies ajudam a evitar a detecção e contornar as restrições.
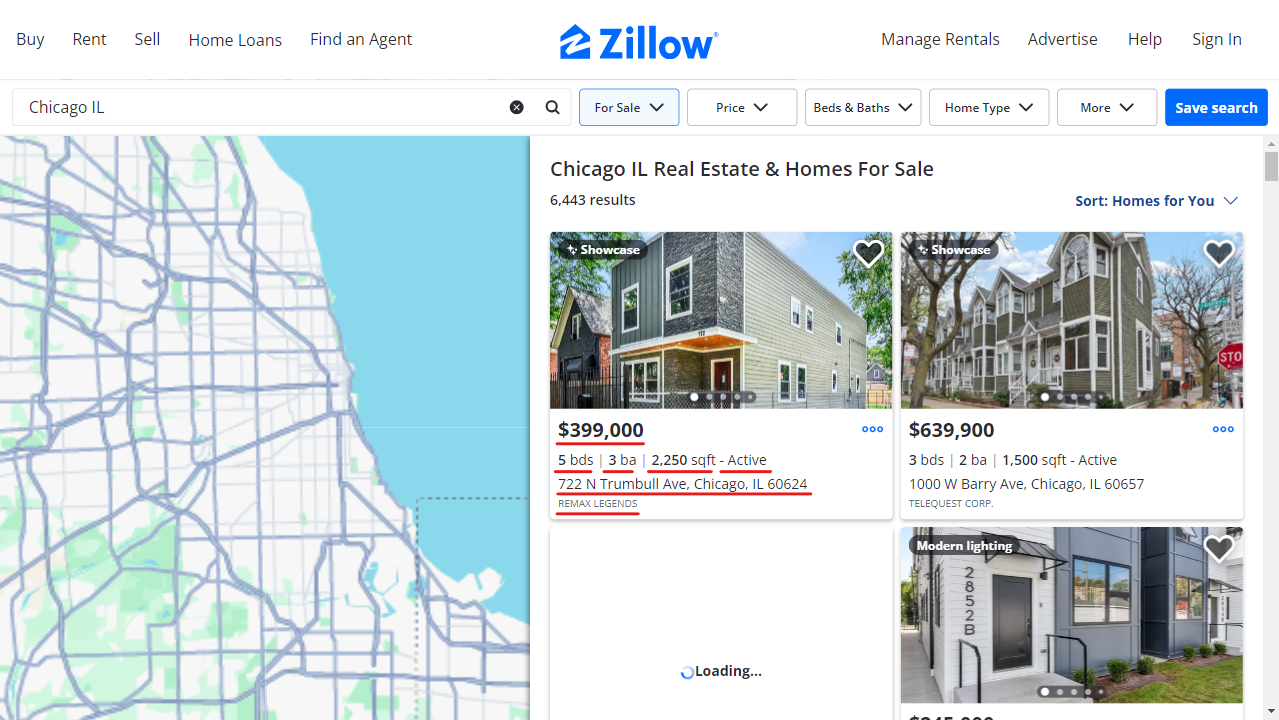
Vamos coletar anúncios de imóveis para Chicago (Illinois), extraindo as seguintes informações para cada propriedade:
Comece criando um ambiente virtual e instalando os pacotes necessários. Você também pode usar Conda ou Poetry, se preferir.
python -m venv zillow_envsource
zillow_env/bin/activate # Windows: zillow_env\\Scripts\\activate
pip install playwright python-dotenv
playwright install
Crie um .env arquivo para armazenar suas credenciais do Massive Proxy com segurança.
PROXY_SERVER="your_proxy_server"
PROXY_USERNAME="your_username"
PROXY_PASSWORD="your_password"
Configure credenciais de proxy e bloqueie ativos desnecessários para otimizar o desempenho e evitar a detecção.
class Config:
PROXY_SERVER = os.getenv("PROXY_SERVER")
PROXY_USERNAME = os.getenv("PROXY_USERNAME")
PROXY_PASSWORD = os.getenv("PROXY_PASSWORD")
BLOCKED_RESOURCES = ["stylesheet", "image", "media", "font", "imageset"]
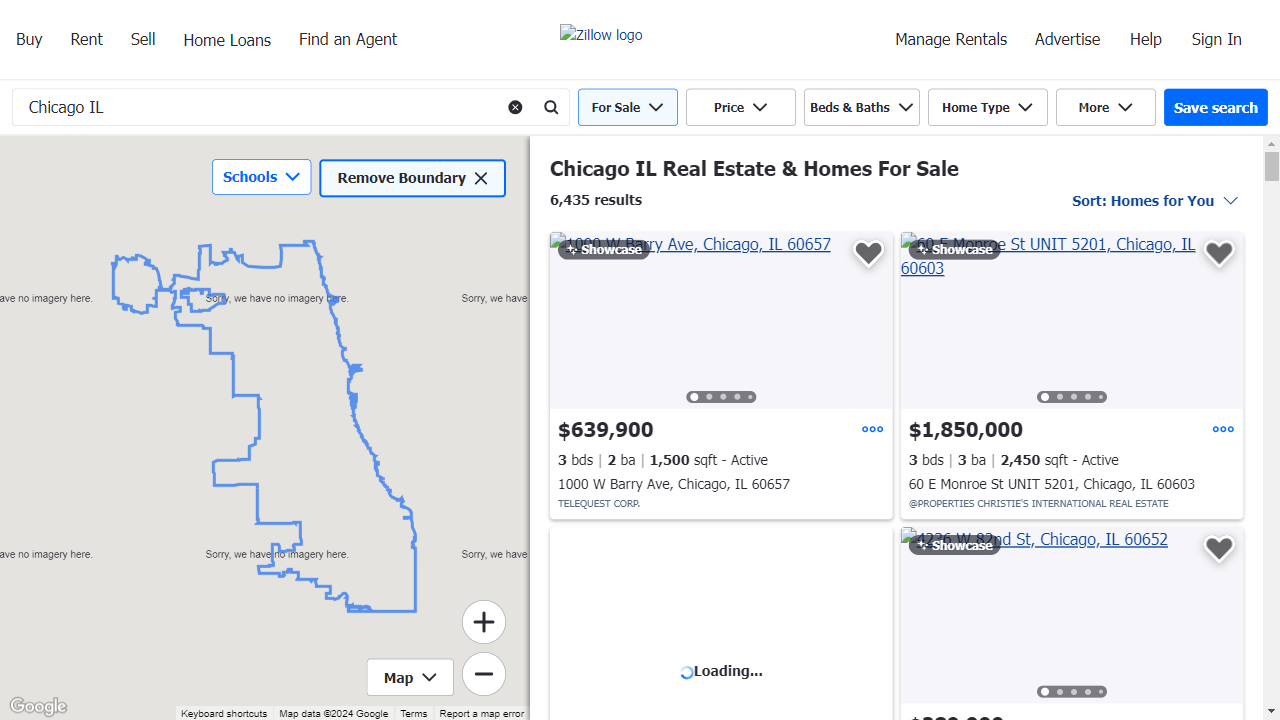
O bloqueio de recursos desnecessários, como fontes e imagens, acelera o processo de coleta.
Veja um exemplo da aparência da página quando os recursos são bloqueados:
Aqui, definimos um contexto de navegador que encaminha solicitações por meio de Massive e filtra conteúdo indesejado.
class AsyncZillowSearchScraper:
def __init__(self, headless: bool = True):
self.headless = headless
self.playwright = None
self.browser = None
self.context = None
async def __aenter__(self):
self.playwright = await async_playwright().start()
browser_config = {"headless": self.headless}
if Config.PROXY_SERVER:
browser_config["proxy"] = {
"server": Config.PROXY_SERVER,
"username": Config.PROXY_USERNAME,
"password": Config.PROXY_PASSWORD,
}
self.browser = await self.playwright.chromium.launch(**browser_config)
self.context = await self.browser.new_context()
await self.context.route("**/*", self._route_handler)
return self
async def _route_handler(self, route):
if route.request.resource_type in Config.BLOCKED_RESOURCES:
await route.abort()
else:
await route.continue_()
Cada propriedade no Zillow está contida em um <li> etiqueta. Esses <li> as tags têm uma classe que começa com ListItem, e cada tag representa uma única listagem de propriedades. Dentro desses <li> etiquetas, você encontrará todos os principais detalhes sobre a propriedade, como endereço, preço e características da propriedade
.
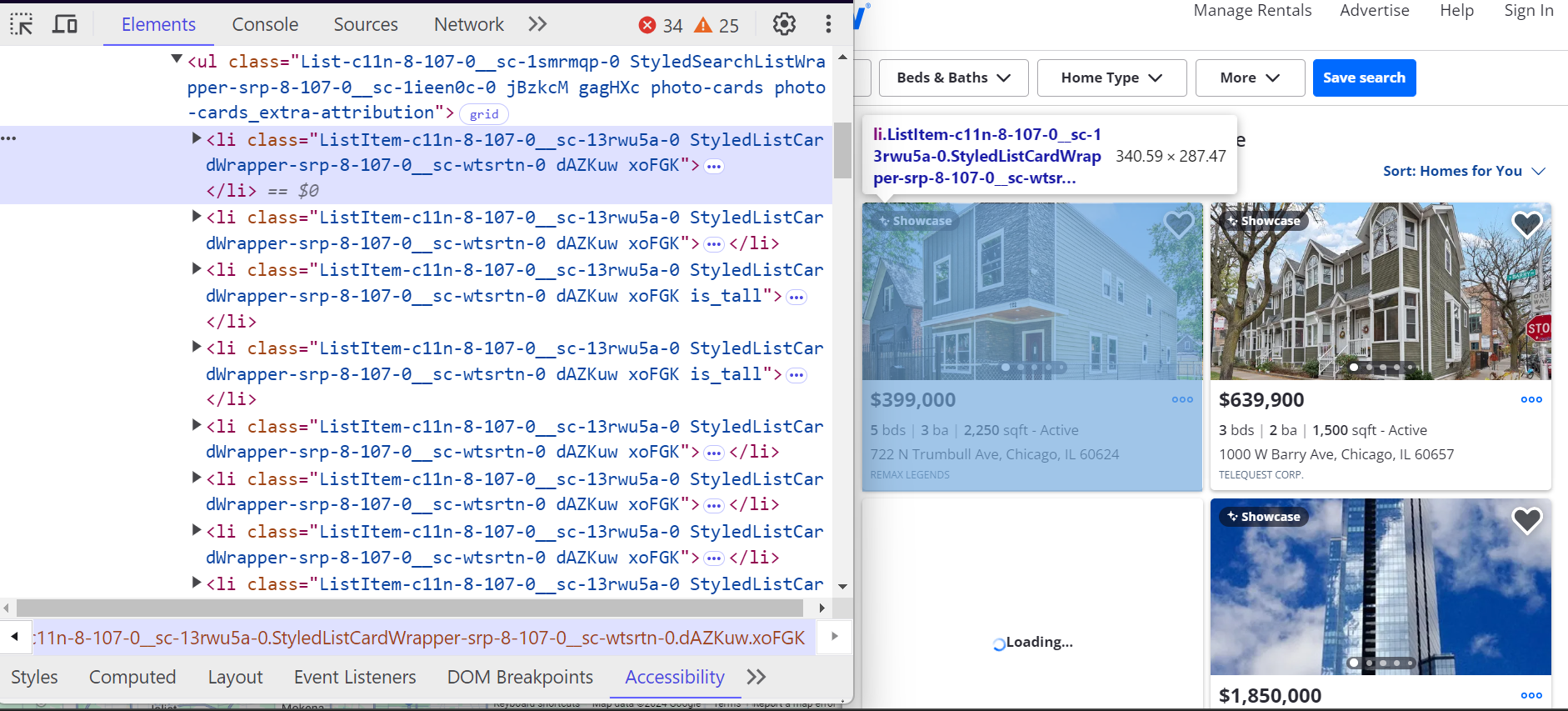
Veja como esses <li> as tags são estruturadas:
Detalhes adicionais, como o número de quartos, banheiros e metragem quadrada, estão aninhados em <ul> listas.
Veja como analisamos anúncios de propriedades individuais:
class ListingParser:
@staticmethod
async def extract_listing_details(listing) -> Optional[Dict]:
try:
data_container = await listing.query_selector(
'div[class*="property-card-data"]'
)
if not data_container:
return None
# Extract basic details
details = {
"address": None,
"status": None,
"price": None,
"bedrooms": None,
"bathrooms": None,
"square_feet": None,
"listing_company": None,
"url": None,
}
# Get address
if address_elem := await data_container.query_selector(
'address[data-test="property-card-addr"]'
):
details["address"] = ListingParser.clean_text(
await address_elem.text_content()
)
# Get price
if price_elem := await data_container.query_selector(
'span[data-test="property-card-price"]'
):
details["price"] = ListingParser.clean_text(
await price_elem.text_content()
)
# Get property URL
if url_elem := await data_container.query_selector(
'a[data-test="property-card-link"]'
):
if url := await url_elem.get_attribute("href"):
details["url"] = (
f"<https://www.zillow.com>{url}"
if not url.startswith("http")
else url
)
# ...
return details
except Exception as e:
logger.error(f"Error extracting listing details: {e}")
return None
Simule a rolagem para carregar mais anúncios dinamicamente:
async def _scroll_and_get_listings(self, page):
last_count = 0
attempts = 0
MAX_ATTEMPTS = 20
while attempts < MAX_ATTEMPTS:
listings = await page.query_selector_all('article[data-test="property-card"]')
current_count = len(listings)
if current_count == last_count:
break
last_count = current_count
await page.evaluate("window.scrollBy(0, 500)")
await asyncio.sleep(1)
attempts += 1
return listings
Clique na próxima página (>) botão para navegar por outras páginas.
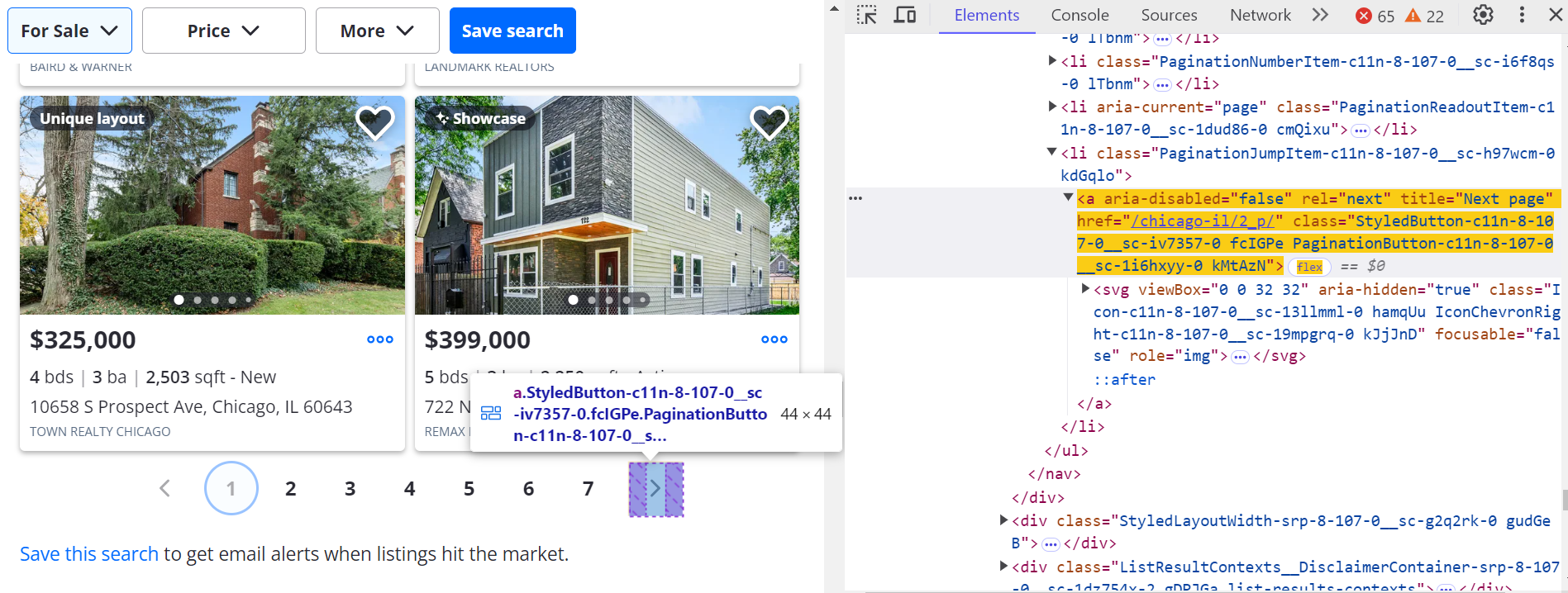
Para ir para a próxima página:
next_button = await page.query_selector('a[title="Next page"]:not([disabled])')
if next_button:
await next_button.click()
await asyncio.sleep(3)
Salve seus dados copiados do Zillow em um arquivo JSON. Você também pode convertê-lo em CSV posteriormente.
class ResultsSaver:
@staticmethod
def save_results(data, filename="zillow_listings.json"):
with open(filename, "w", encoding="utf-8") as file:
json.dump(data, file, indent=4, ensure_ascii=False)
logger.info(f"Saved {len(data)} listings")
@staticmethod
def load_existing_results(filename="zillow_listings.json"):
try:
if os.path.exists(filename):
with open(filename, "r", encoding="utf-8") as file:
return json.load(file)
except Exception as e:
logger.error(f"Error loading data: {e}")
return []
Junte tudo em uma função principal para iniciar o raspador, extrair dados e salvar os resultados.
async def main():
search_url = "https://www.zillow.com/chicago-il/"
max_pages = None # Set to a number to limit pages
async with AsyncZillowSearchScraper(headless=False) as scraper:
results = await scraper.scrape_search_results(search_url, max_pages=max_pages)
print(f"\\nTotal listings scraped: {len(results)}")
if results:
print("\\nSample listing:")
print(json.dumps(results[0], indent=2, ensure_ascii=False))
if __name__ == "__main__":
asyncio.run(main())
Depois de configurar e executar com sucesso seu raspador Zillow usando proxies Massive, sua saída ficará mais ou menos assim:
[
{
"address": "722 N Trumbull Ave, Chicago, IL 60624",
"status": "Active",
"price": "$399,000",
"bedrooms": "5",
"bathrooms": "3",
"square_feet": "2250",
"listing_company": "REMAX LEGENDS",
"url": "https://www.zillow.com/homedetails/722-N-Trumbull-Ave-Chicago-IL-60624/3810331_zpid/",
}
]Os dados agora estão estruturados e utilizáveis, perfeitos para análises imobiliárias, painéis ou ferramentas de investimento.
Você pode acessar o código completo para coletar dados do Zillow usando proxies Massive em GitHub Gist.
A coleta de dados imobiliários da Zillow oferece uma vantagem na compreensão do mercado, no rastreamento de propriedades e nas ferramentas de automação predial. Com os proxies residenciais da Massive, você pode:
Pronto para criar seu próprio raspador de dados Zillow? Inscreva-se no Massive Proxies hoje.

Copyright Massive; Massive is a registered trademark of Massive Computing, Inc.




