How to Scrape Zillow Data With Massive - A Beginner’s Guide

Jason Grad
Co-founder
March 28, 2025
.png)
Zillow is one of the largest real estate websites in the U.S., offering a treasure trove of real estate listings, property prices, and market analytics. But scraping Zillow isn’t easy—its anti-bot defenses can quickly shut down your data extraction efforts.
This guide walks you through how to scrape Zillow property data effectively using Massive’s residential proxies and Python with Playwright. You’ll learn how to bypass detection, extract real estate data reliably, and scale your scraping workflow like a pro.
Zillow real estate data is a goldmine for:
Whether you’re a data analyst, a real estate investor, or a developer building automation tools, scraping data from Zillow can provide valuable insights into the real estate market.
Scraping data from Zillow presents significant challenges due to its robust anti-bot systems:
Here’s an example of what happens when a scraper gets blocked by human verification:

That’s where proxies—specifically residential proxies—come in.
Proxies act as intermediaries between your scraper and the web. They’re essential for web scraping Zillow because they help:
However, not all proxies are created equal.
From experience, residential proxies outperform datacenter ones for scraping Zillow. Here’s why:
If your goal is consistent, scalable scraping without blocks, residential is the way to go.
Create your account at partners.joinmassive.com and choose a plan for your needs. After that, go to the Massive Dashboard to retrieve your proxy credentials (username and password).
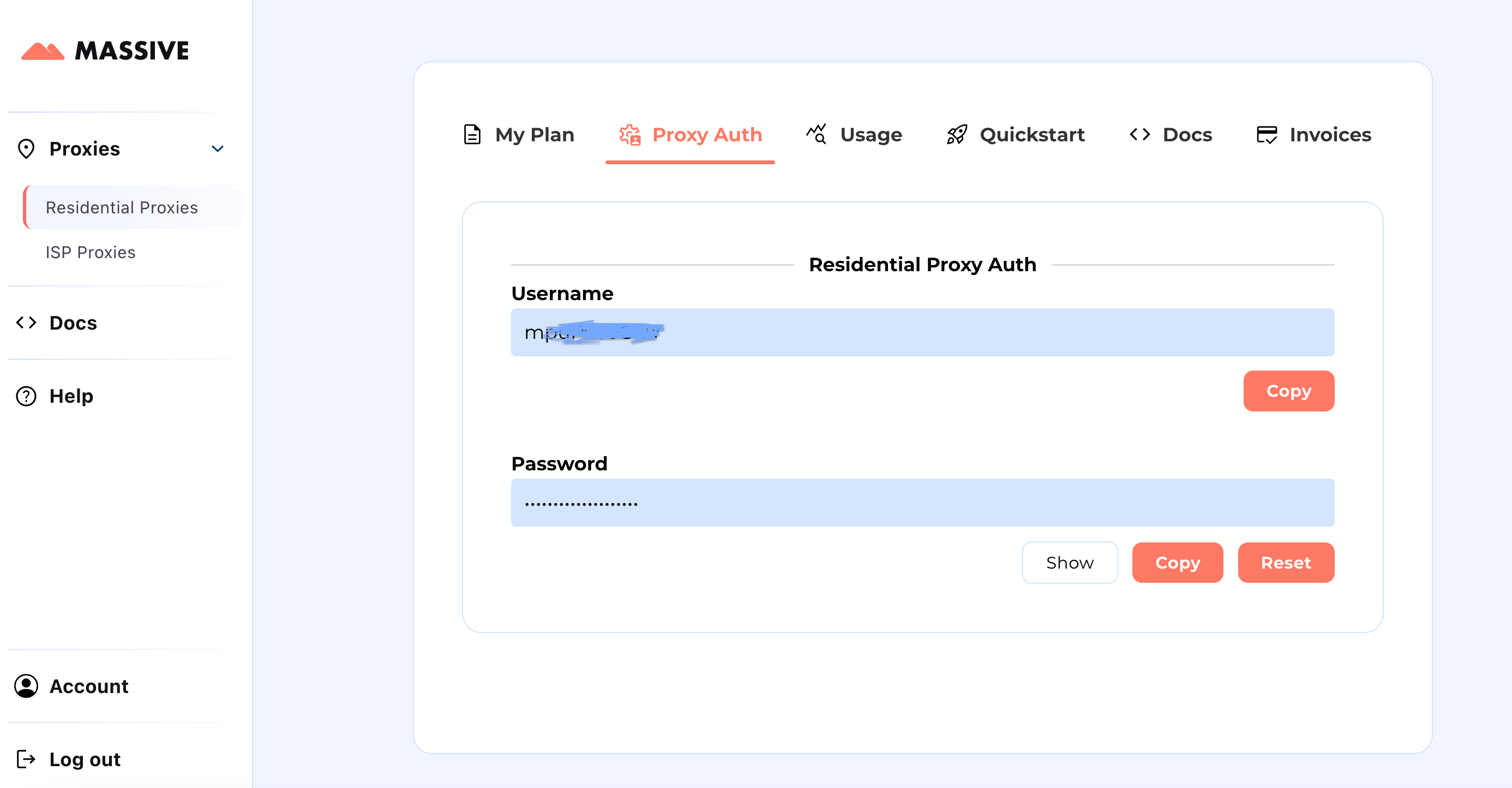
Configuration Steps:
Visit the Quickstart section to customize your proxy settings:
Once configured, you'll get a ready-to-use cURL command for your specific use case.
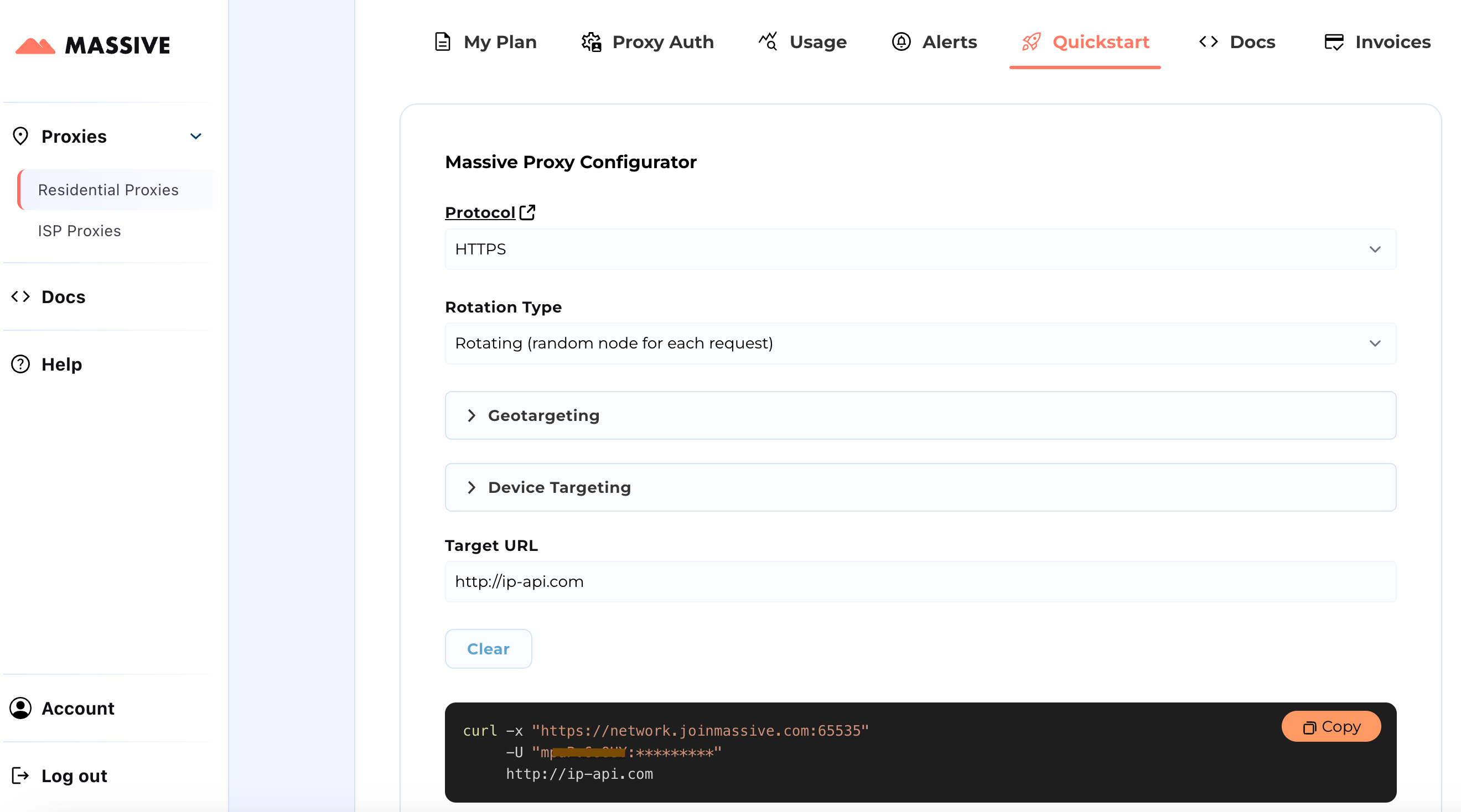
For advanced features like location-based targeting and sticky sessions, refer to the Massive Documentation. The docs provide step-by-step instructions for getting the most out of Massive Residential Proxies.
With this setup, you can use Massive Proxies to scrape Zillow product data from a specific region.
Let’s build a Zillow scraper using Playwright and Massive Proxies. Playwright automates browser interactions and effectively handles dynamic content, while proxies help to avoid detection and bypass restrictions.
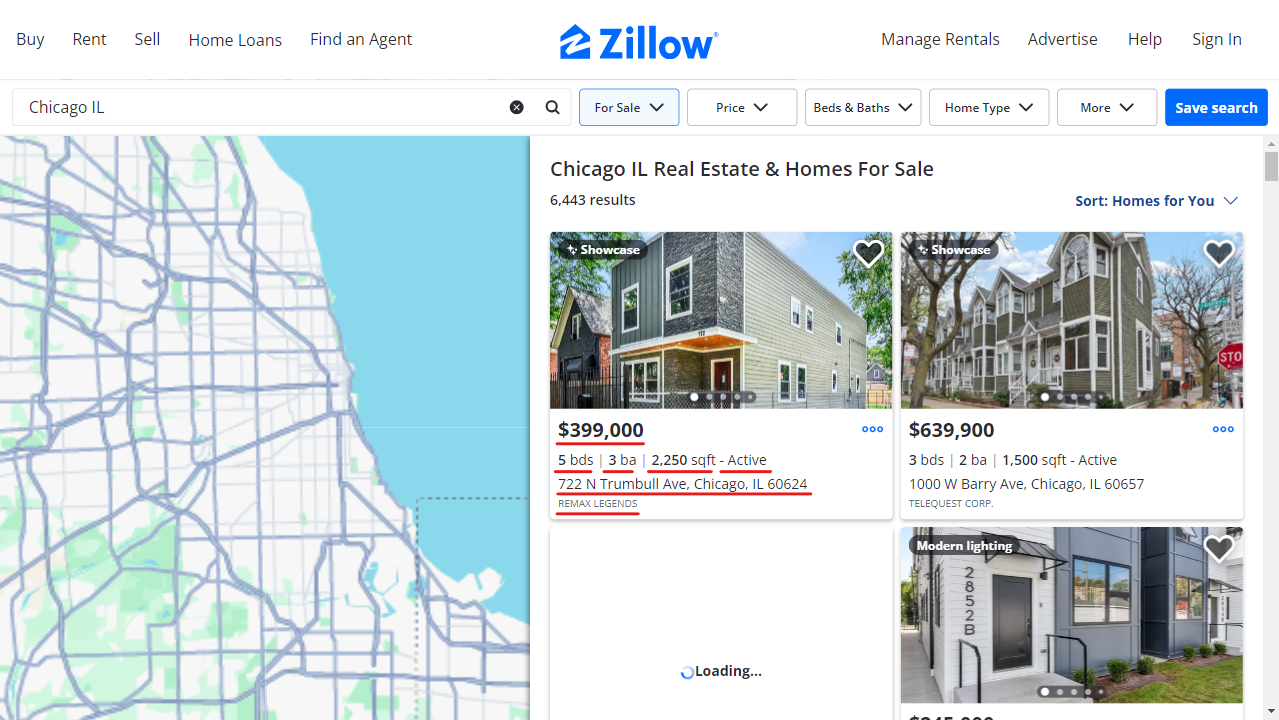
We’ll scrape real estate listings for Chicago IL, extracting the following information for each property:
Start by creating a virtual environment and installing the required packages. You can also use Conda or Poetry if preferred.
python -m venv zillow_envsource
zillow_env/bin/activate # Windows: zillow_env\\Scripts\\activate
pip install playwright python-dotenv
playwright install
Create a .env file to store your Massive proxy credentials securely.
PROXY_SERVER="your_proxy_server"
PROXY_USERNAME="your_username"
PROXY_PASSWORD="your_password"
Set up proxy credentials and block unnecessary assets to optimize performance and avoid detection.
class Config:
PROXY_SERVER = os.getenv("PROXY_SERVER")
PROXY_USERNAME = os.getenv("PROXY_USERNAME")
PROXY_PASSWORD = os.getenv("PROXY_PASSWORD")
BLOCKED_RESOURCES = ["stylesheet", "image", "media", "font", "imageset"]
Blocking unnecessary resources like fonts and images speeds up the scraping process.
Here’s an example of how the page looks when resources are blocked:
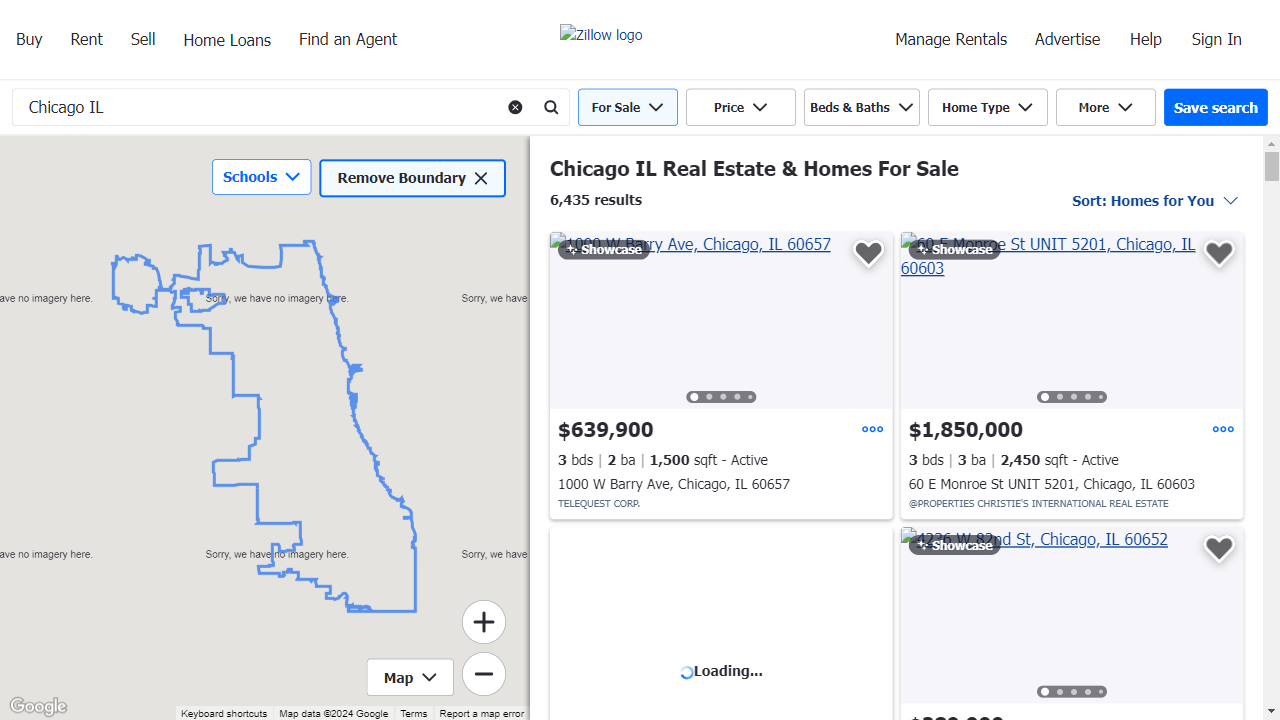
Here, we define a browser context that routes requests through Massive and filters unwanted content.
class AsyncZillowSearchScraper:
def __init__(self, headless: bool = True):
self.headless = headless
self.playwright = None
self.browser = None
self.context = None
async def __aenter__(self):
self.playwright = await async_playwright().start()
browser_config = {"headless": self.headless}
if Config.PROXY_SERVER:
browser_config["proxy"] = {
"server": Config.PROXY_SERVER,
"username": Config.PROXY_USERNAME,
"password": Config.PROXY_PASSWORD,
}
self.browser = await self.playwright.chromium.launch(**browser_config)
self.context = await self.browser.new_context()
await self.context.route("**/*", self._route_handler)
return self
async def _route_handler(self, route):
if route.request.resource_type in Config.BLOCKED_RESOURCES:
await route.abort()
else:
await route.continue_()
Each property on Zillow is contained within a <li> tag. These <li> tags have a class that starts with ListItem, and each tag represents a single property listing. Inside these <li> tags, you’ll find all the key details about the property, such as the address, price, and property features
.
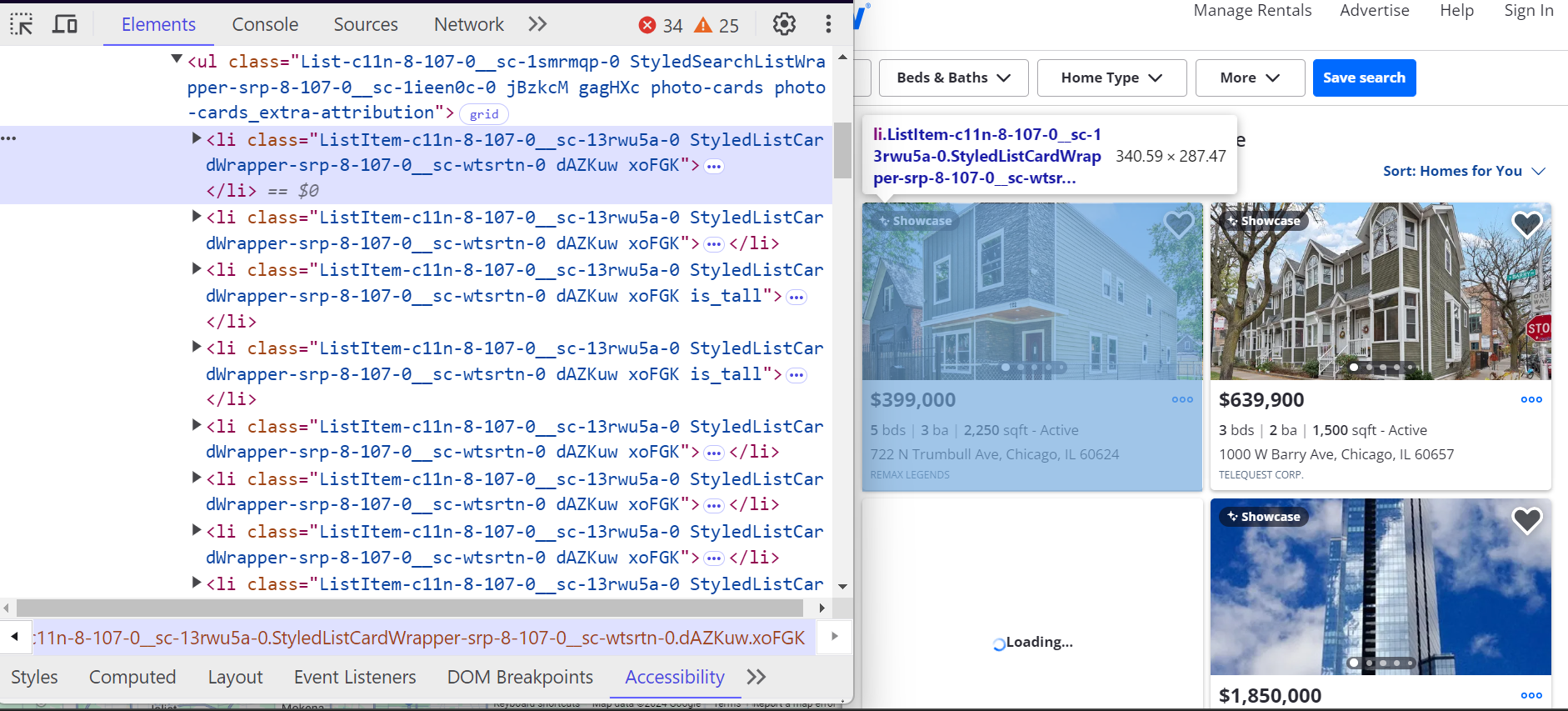
Here’s how these <li> tags are structured:
Additional details like the number of bedrooms, bathrooms, and square footage are nested within <ul> lists.
Here's how we parse individual property listings:
class ListingParser:
@staticmethod
async def extract_listing_details(listing) -> Optional[Dict]:
try:
data_container = await listing.query_selector(
'div[class*="property-card-data"]'
)
if not data_container:
return None
# Extract basic details
details = {
"address": None,
"status": None,
"price": None,
"bedrooms": None,
"bathrooms": None,
"square_feet": None,
"listing_company": None,
"url": None,
}
# Get address
if address_elem := await data_container.query_selector(
'address[data-test="property-card-addr"]'
):
details["address"] = ListingParser.clean_text(
await address_elem.text_content()
)
# Get price
if price_elem := await data_container.query_selector(
'span[data-test="property-card-price"]'
):
details["price"] = ListingParser.clean_text(
await price_elem.text_content()
)
# Get property URL
if url_elem := await data_container.query_selector(
'a[data-test="property-card-link"]'
):
if url := await url_elem.get_attribute("href"):
details["url"] = (
f"<https://www.zillow.com>{url}"
if not url.startswith("http")
else url
)
# ...
return details
except Exception as e:
logger.error(f"Error extracting listing details: {e}")
return None
Simulate scrolling to load more listings dynamically:
async def _scroll_and_get_listings(self, page):
last_count = 0
attempts = 0
MAX_ATTEMPTS = 20
while attempts < MAX_ATTEMPTS:
listings = await page.query_selector_all('article[data-test="property-card"]')
current_count = len(listings)
if current_count == last_count:
break
last_count = current_count
await page.evaluate("window.scrollBy(0, 500)")
await asyncio.sleep(1)
attempts += 1
return listings
Click the Next Page (>) button to navigate through other pages.
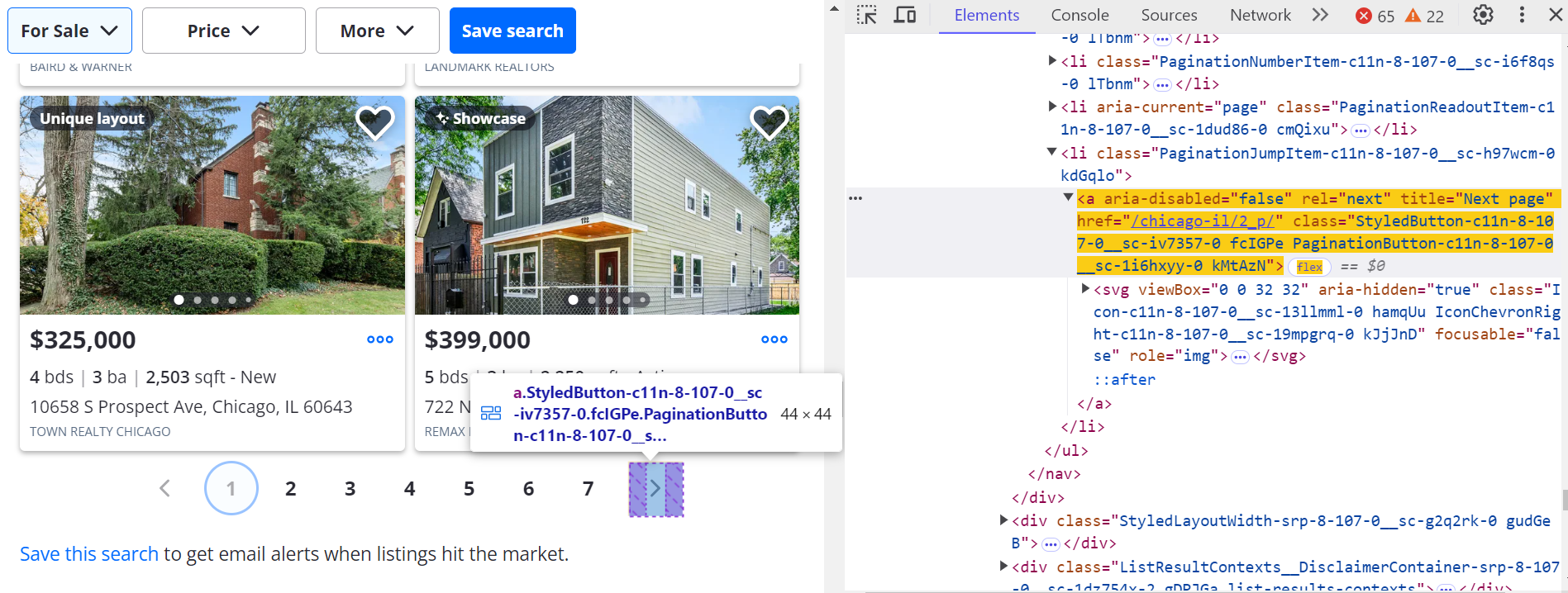
To go to the next page:
next_button = await page.query_selector('a[title="Next page"]:not([disabled])')
if next_button:
await next_button.click()
await asyncio.sleep(3)
Save your scraped Zillow data to a JSON file. You can also convert it to CSV later.
class ResultsSaver:
@staticmethod
def save_results(data, filename="zillow_listings.json"):
with open(filename, "w", encoding="utf-8") as file:
json.dump(data, file, indent=4, ensure_ascii=False)
logger.info(f"Saved {len(data)} listings")
@staticmethod
def load_existing_results(filename="zillow_listings.json"):
try:
if os.path.exists(filename):
with open(filename, "r", encoding="utf-8") as file:
return json.load(file)
except Exception as e:
logger.error(f"Error loading data: {e}")
return []
Tie it all together in a main function to launch the scraper, extract data, and save the results.
async def main():
search_url = "https://www.zillow.com/chicago-il/"
max_pages = None # Set to a number to limit pages
async with AsyncZillowSearchScraper(headless=False) as scraper:
results = await scraper.scrape_search_results(search_url, max_pages=max_pages)
print(f"\\nTotal listings scraped: {len(results)}")
if results:
print("\\nSample listing:")
print(json.dumps(results[0], indent=2, ensure_ascii=False))
if __name__ == "__main__":
asyncio.run(main())
Once you've successfully set up and run your Zillow scraper using Massive proxies, your output will look something like this:
[
{
"address": "722 N Trumbull Ave, Chicago, IL 60624",
"status": "Active",
"price": "$399,000",
"bedrooms": "5",
"bathrooms": "3",
"square_feet": "2250",
"listing_company": "REMAX LEGENDS",
"url": "https://www.zillow.com/homedetails/722-N-Trumbull-Ave-Chicago-IL-60624/3810331_zpid/",
}
]The data is now structured and usable—perfect for real estate analytics, dashboards, or investment tools.
You can access the complete code for scraping Zillow data using Massive proxies in GitHub Gist.
Scraping Zillow real estate data gives you an edge in understanding the market, tracking properties, and building automation tools. With Massive’s residential proxies, you can:
Ready to build your own Zillow data scraper? Sign up for Massive Proxies today.

Copyright Massive; Massive is a registered trademark of Massive Computing, Inc.