Domine o Web Scraping com Scrapoxy & Massive: evite proibições e escale sem problemas
Jason Grad
Co-founder
February 13, 2025
Table of Contents
+
A captura de dados na Web em grande escala exige um gerenciamento robusto de proxy e IPs confiáveis. Neste guia, saiba como integrar o Scrapoxy aos proxies residenciais premium da Massive para agilizar o gerenciamento de proxy, a rotação de IP e a prevenção de banimentos. Essa integração tornará suas operações de web scraping mais eficientes e escaláveis.
O que é Scrapoxy?
O Scrapoxy é um agregador de proxy de código aberto que centraliza o gerenciamento de proxy em uma única interface. Ele atua como um endpoint unificado para operações de web scraping, eliminando a complexidade de lidar com vários serviços de proxy de forma independente.
Principais características do Scrapoxy
Painel de controle unificado: gerencie todos os seus proxies por meio de um único painel
Distribuição inteligente de tráfego: Rotação automatizada de proxy e roteamento inteligente de solicitações
Redução de custos: Escalabilidade dinâmica de proxy que pode reduzir os custos em até 80%
Prevenção avançada de proibições: Detecção e remoção automáticas de IPs bloqueados
Suporte para vários provedores: Compatível com proxies residenciais, de datacenter e móveis
A integração do gerenciamento inteligente de proxy da Scrapoxy com os proxies residenciais de alto desempenho da Massive cria uma infraestrutura de raspagem robusta. Veja o porquê:
Proxies éticos e de alto desempenho: IPs residenciais 100% de origem ética em mais de 195 locais.
Confiabilidade e velocidade: Taxa de sucesso de 99,8%, tempo de resposta de <0,8s e tempo de atividade de 99,9%.
Segmentação avançada: Filtre por país, estado, cidade, ASN e CEP.
Automação perfeita: Suporta sessões fixas e rotativas, estatísticas ao vivo e tópicos ilimitados.
Flexibilidade e Segurança: Ele suporta HTTP (S) e SOCKS5, é compatível com GDPR/CCPA e é fácil de integrar.
Acessível e escalável: O preço começa em $4,49/GB com sessões simultâneas ilimitadas. Entre em contato com nossa equipe de vendas para obter descontos acima de 1 TB/mês.
Como configurar proxies massivos com o Scrapoxy
Siga as etapas abaixo para configurar tudo com facilidade.
Etapa 1: obtenha proxies residenciais massivos
Inscreva-se no Massive Proxies: Se você é novo no Massive, inscreva-se em uma conta. Escolha um plano para suas necessidades.
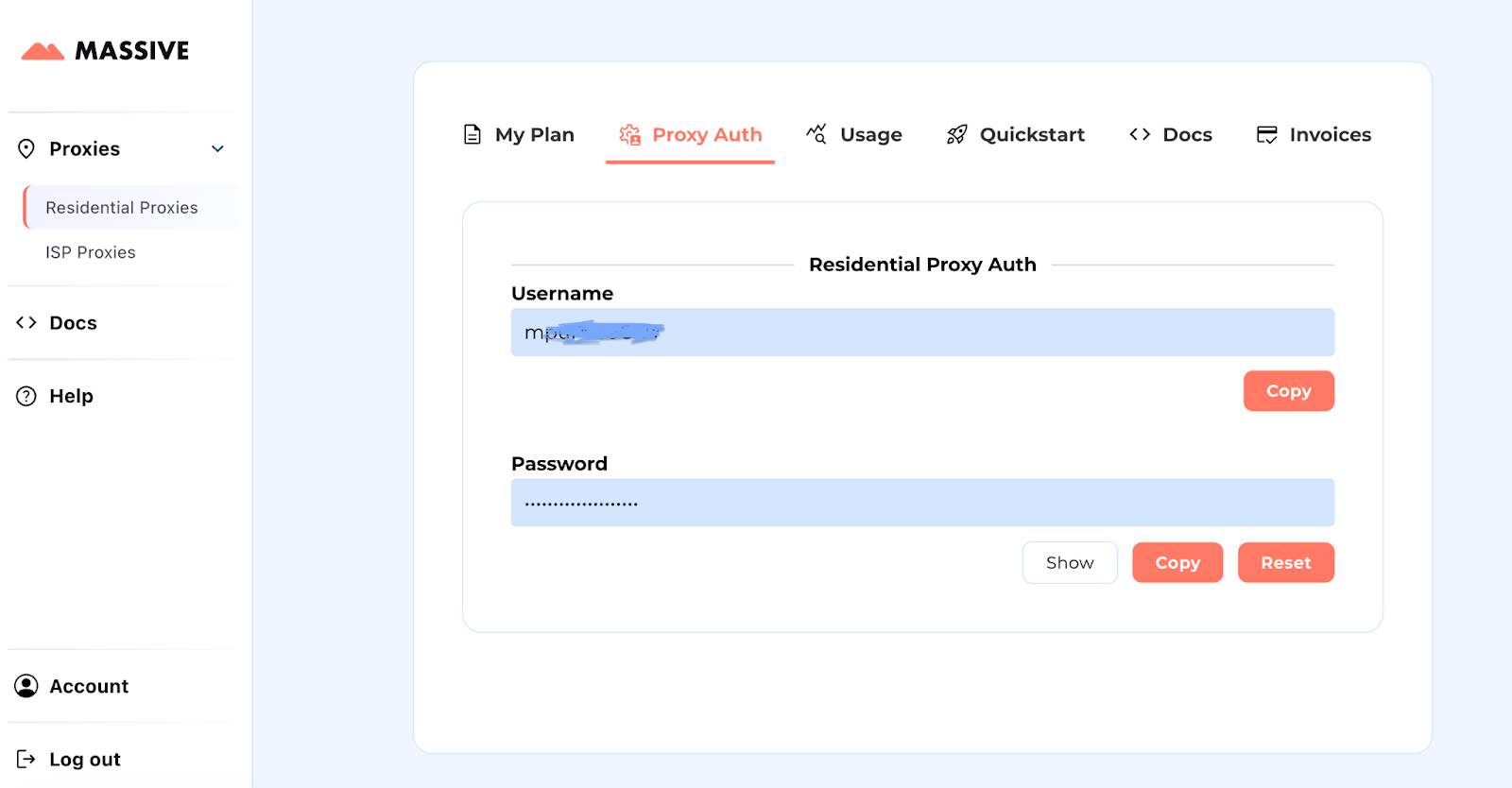
Acesse suas credenciais de proxy: Depois de se inscrever, acesse o Painel enorme para recuperar suas credenciais de proxy (nome de usuário e senha). Salve essas credenciais para a configuração do Scrapoxy.
Acesse a interface do usuário do Scrapoxy: Navegue até http://localhost:8890 e faça login usando o nome de usuário e a senha fornecidos no comando acima.
Etapa 3: criar um novo projeto no Scrapoxy
Depois de fazer login, você será solicitado a criar um novo projeto. Siga estas etapas:
Dê um nome ao seu projeto: Atribua um nome personalizado ao seu projeto.
Defina proxies mínimos: Defina o número mínimo de proxies a serem mantidos on-line quando o status do projeto for CALM.
Ativar proxies de rotação automática: Defina um intervalo de atraso para rotação automática do proxy.
Ativar escalabilidade automática para cima/para baixo: Ajusta automaticamente o número de proxies ativos com base na demanda.
Defina as configurações avançadas: Habilite recursos como MITM para HTTPS, biscoitos pegajosos, Substituição do agente de usuário, e Embaralhamento de cifras TLS para aprimorar sua configuração de raspagem.
Crie o projeto: Clique Criar para finalizar a configuração.
Etapa 4: configurar o conector massivo
1. Escolha Massive no Marketplace: Na interface do Scrapoxy, pesquise e selecione Maciço. Clique Criar para configurar o conector.
2. Insira suas credenciais do Massive (nome de usuário e senha da Etapa 1). Clique Criar para salvar as credenciais.
3. Crie o conector: Configure o conector com as seguintes configurações:
Credenciais: Selecione as credenciais que você acabou de criar.
Nome: Atribua um nome personalizado ao conector.
# Proxies: Defina o limite de proxy com base nas suas necessidades.
Tempo limite dos proxies: Defina quanto tempo o Scrapoxy espera antes de tentar novamente um proxy.
País: Escolha proxies de locais específicos ou permita todos.
Clique Criar para finalizar o conector.
4. Inicie o conector: Alterne o Iniciar/parar este conector botão para ativar o conector.
Etapa 5: integre o Scrapoxy ao seu código
Agora que tudo está configurado, você pode integrar o Scrapoxy aos seus scripts de raspagem. Aqui está um exemplo usando Python com o pedidos biblioteca:
O Scrapoxy fornece informações detalhadas sobre o uso do proxy. Use o Proxies, Cobertura, e Métricas guias para monitorar proxies ativos, suas localizações, velocidades de upload/download, contagens de solicitações e status.
Encerrando
Ao integrar Scrapoxy com Proxies massivos, você pode criar uma configuração de raspagem econômica e resistente a proibições que pode ser escalada sem esforço. O gerenciamento inteligente de proxy do Scrapoxy combinado com os proxies residenciais de alto desempenho da Massive garante acesso rápido, confiável e compatível à web.










.png)




